 小菜学编程
小菜学编程

《Unix环境高级编程》第一次读书分享会由廖同学主持,主要讲解 文件操作 。 Unix/Linux 提供了这几个系统调用来操作文件:
- open ,操作前先打开文件,获得一个 文件描述符 ( file descriptor );
- read ,从文件指定位置读取数据(传打开文件的描述符);
- write ,将数据写到文件指定位置(传文件描述符);
- lseek ,更新文件当前偏移量,偏移量决定 read 和 write 读写位置;
- close ,操作完毕后关闭文件,回收系统资源,并释放文件描述符;
Unix/Linux 文件操作很简单,无非是打开、关闭、读写和指针移动( lseek ),对吧?尽管如此,简单的东西还是有很多需要考究的地方。
为了提高学习效果,增强每位同学的参与感,我特地安排了课前作业。既然是学习文件操作,那就模仿着开发一个 cat 命令呗。
cat 是一个非常简单的 Unix/Linux 命令,用于读取文件数据,并输出到标准输出。但就这么简单的一个作业,初学者还是很难写好。
那么,实现 cat 命令背后都有哪些门道呢?简单的表象下,又暗藏哪些玄机呢?
作业要求
用 C 语言实现 cat 命令,要求基本用法如下:
|
|
具体可以参考系统自带的 cat 命令,查看 man 文档:
|
|
压力测试
每位同学都顺利完成作业,功能上基本没有问题。但其中陈同学编写的程序,只能处理文本文件,无法处理二进制文件,成绩直接垫底。
其余同学代码逻辑上没有问题,又该如何评价呢?
当然是 性能 啦!用一个大文件对他们开发的 cat 命令做压力测试!
首先,我执行 dd 命令生成一个 10G 大、数据全是零字节的数据文件:
|
|
dd 命令用于拷贝文件数据,常用参数列举如下:
- if ,指定输入文件;
- of ,指定输出文件;
- bs ,指定数据块大小;
- count ,指定拷贝数据块个数;
上面这行命令的意思是从 /dev/zero 拷贝 10240 个数据块到 10g.bin 文件,数据块大小为 1M 。总数据拷贝量为 $bs \times count$ ,即 $1M \times 10240$ ,也就是 10G 。
注意到,/dev/zero 是一个特殊的设备文件,读取时不断返回零字节,无穷无尽。因此,这个 dd 命令执行完毕后,便生成了一个 10G 大的文件 10g.bin ,数据都是零。
然后,我执行这段 Shell 脚本,分别对每位同学提交的 cat 命令进行压力测试:
|
|
for 循环对每个 cat 程序执行五轮压测,每轮压测执行 cat 命令处理 10g.bin 文件,同时记录耗时( time )。注意到,每个版本的 cat 程序压测前,均执行系统 cat 命令一遍(第 2 行),保证测试环境(系统文件缓存)是一样的。
压测跑下来后,结果有点意外,不同版本的 cat 表现差异有点大:
| 作者 | 用户态耗时 | 内核态耗时 | 总耗时 | 排名 |
|---|---|---|---|---|
| 林同学 | 245.534 | 4.349 | 249.902 | 4 |
| 廖同学 | 0.641 | 3.416 | 4.056 | 2 |
| 陈同学 ❌ | 1.176 | 2.599 | 3.575 | 5 |
| 黄同学 | 169.108 | 4.064 | 173.181 | 3 |
| 系统内置 | 0.041 | 1.973 | 2.014 | 1 |
系统自带的 cat 命令,在 2 秒左右就完成了对 10G 数据的处理。而四位同学中提交的程序中,表现最好的是 4 秒左右,表现最差的耗时竟然高达 250 秒。其中,陈同学那份由于程序存在逻辑错误,成绩无效。
cat 命令只是读取文件并打到标准输出,再简单不过了,不同实现性能竟有天壤之别!那么,这究竟是为什么呢?
接下来,我们就从源码角度出发,来分析分析这其中的门道。
林同学
我们先来围观耗时最长的林同学版本,详细测试数据如下:
| 测试 | 用户态耗时 | 内核态耗时 | 总耗时 |
|---|---|---|---|
| 第一轮 | 247.410 | 4.346 | 251.773 |
| 第二轮 | 246.857 | 4.343 | 251.213 |
| 第三轮 | 246.453 | 4.527 | 251.001 |
| 第四轮 | 240.329 | 4.232 | 244.573 |
| 第五轮 | 246.623 | 4.297 | 250.948 |
| 平均 | 245.534 | 4.349 | 249.901 |
| 最优 | 240.329 | 4.232 | 244.573 |
| 最差 | 247.410 | 4.527 | 251.773 |
可以看到林同学的 cat 程序在用户态干了很多事,但标准 cat 命令用户态耗时几乎为零,这是为什么呢?
|
|
我们围观林同学的程序源码,发现它是用 C 语言的标准 I/O 库来实现,而不是直接通过 read/write 系统调用。C 语言标准 I/O 库屏蔽了不同操作系统读写文件的差异性,并通过在进程内存中缓存数据,合并读写操作进而提高效率。
由于读写时多了一层缓存,因此在某些场景下效率较差。以写操作为例,数据需要先拷贝到标准 I/O 库的缓冲区,然后再调用系统调用拷贝到内核。但如果只是多了一次数据拷贝,林同学的程序耗时不会跟 cat 命令差这么多。
我们注意到林同学程序中的 while 循环,将输入文件数据一个字节一个字节地拷贝到标准输出:
- fgetc ,从输入文件中读取一个字节;
- feof ,判断源文件是否读完;
- fputc ,将这个字节写到标准输出;
由于文件大小为 10GB ,while 循环需要执行 $10 \times 2^{30}$ 次,超过一百亿次!换句话讲,fgetc 和 fputc 分别被调用超过一百亿次!而函数调用是有开销的,需要将调用参数压栈,然后跳到函数代码执行,函数返回还要清理栈。 C++ 中提供了内联函数,直接将函数代码展开,避免函数调用,进而提高执行效率。
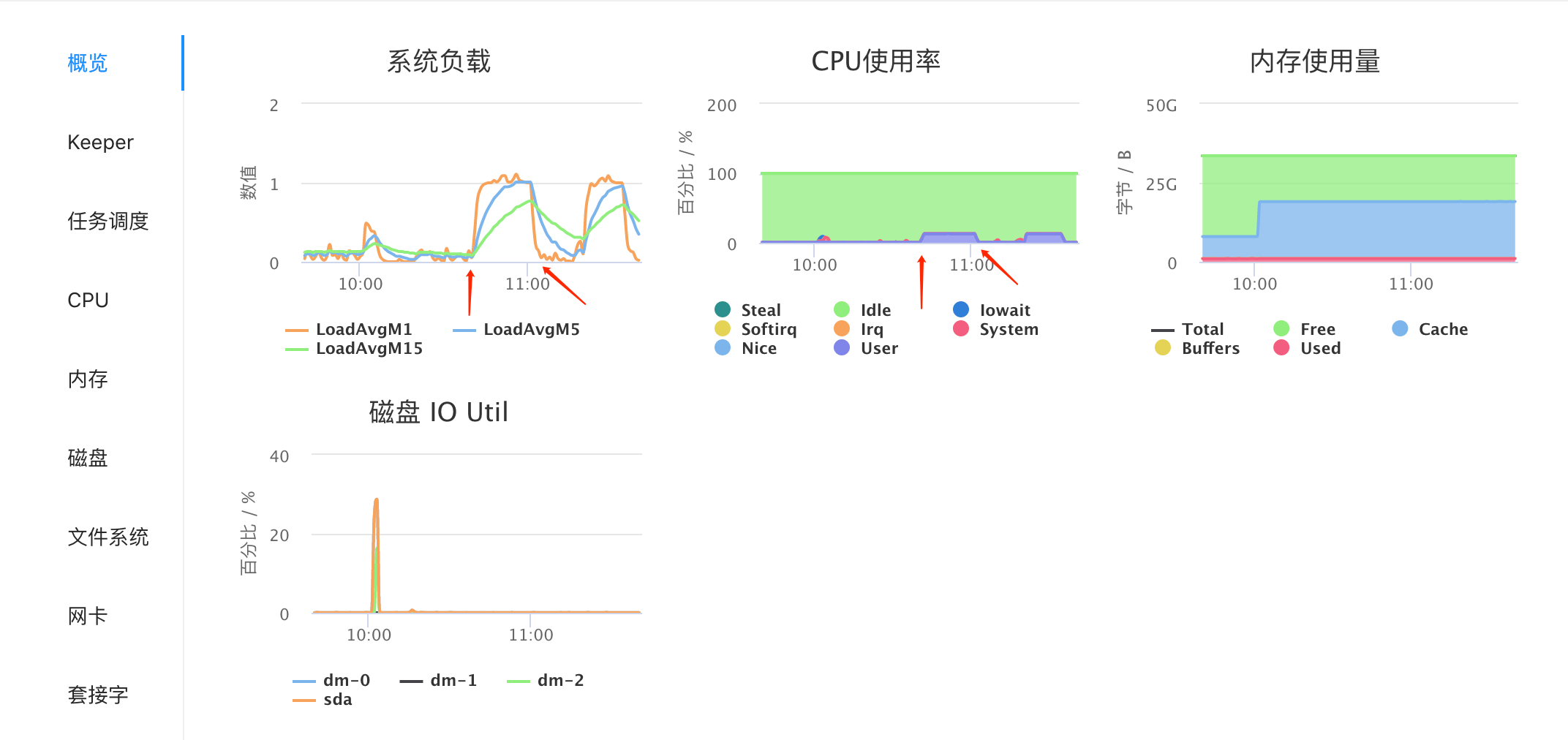
红色箭头分别是压测开始和结束的时间点,压测主机 CPU 是 8 核的,CPU 总体使用率在百分之十几,说明有一个核被跑满了。考虑到林同学程序执行了这么多函数调用,用户态耗时这么多也就不难解释了。
这是一个典型的例子,程序逻辑是正确的,但跑起来后照样犯错。一个合格的研发工程师,不应该写这样的程序。唯有对编程语言,对系统,甚至对底层硬件有足够的了解,才能将程序写好。任重而道远!
黄同学
黄同学的程序表现比林同学稍好一些,但还是很耗时。
我们直接围观他的代码,同样是使用标准 I/O 库来实现的。核心代码是 file_copy 函数,将一个文件的数据拷贝到另一个文件,看起来跟林同学并无二致:
|
|
为什么黄同学的程序表现比林同学稍好一些呢?对比代码猜一猜?
答案是:黄同学的拷贝循环中,函数调用比林同学少一次。林同学调用 feof 判断源文件是否读完,而黄同学直接执行比较操作,省了一次函数调用。正是这次函数调用,让他的程序节约了不少时间。
黄同学每次循环调用 2 个库函数,林同学调用 3 个,他们程序的耗时也大致是 2:3 。
廖同学
表现最好的是廖同学的作品,跟系统自带的 cat 命令比较接近,但耗时还是要长一倍左右。
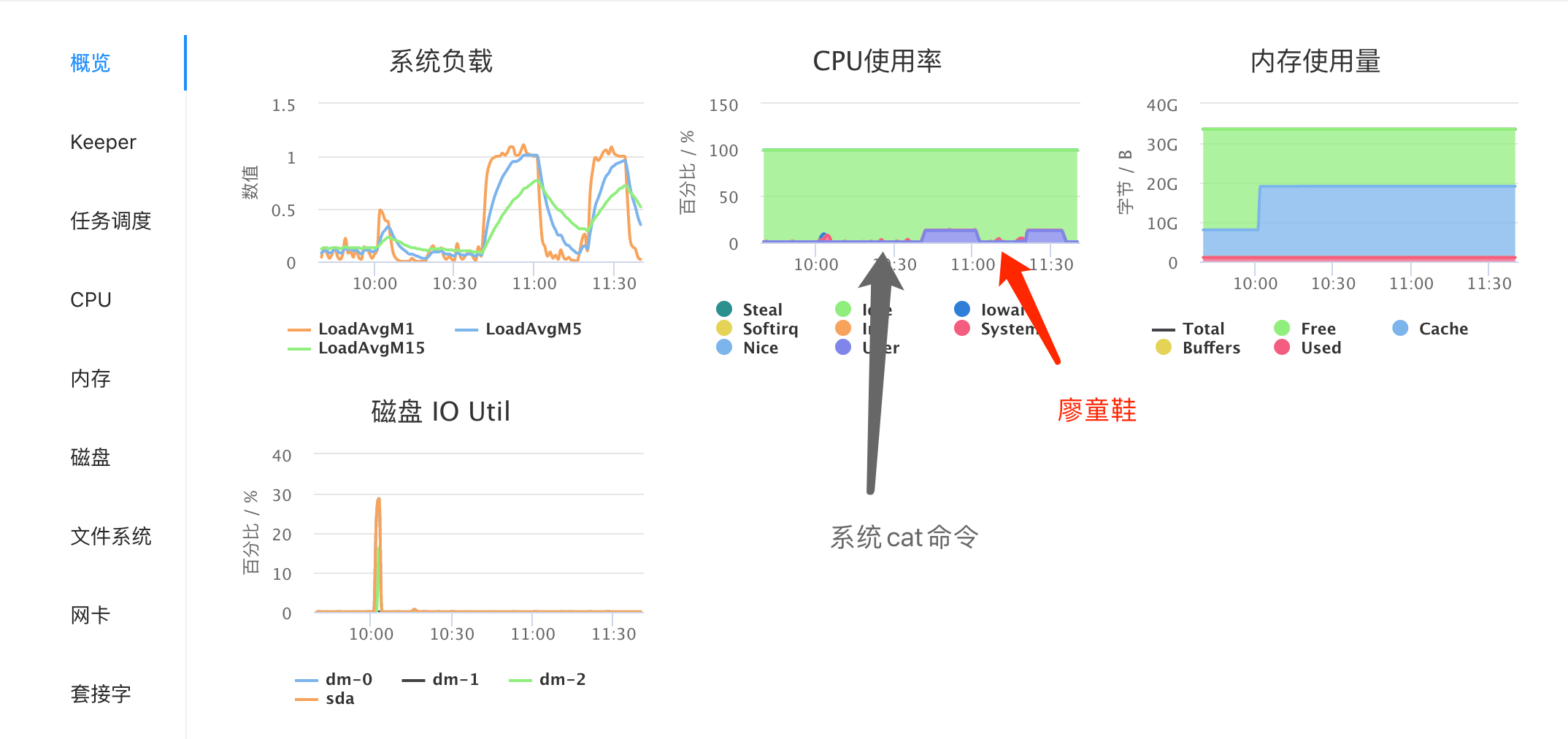
廖同学没有直接用标准 I/O 库,而是直接执行系统调用:
- 调用 open 系统调用打开文件;
- 循环拷贝数据:
- 调用 read 系统调用从源文件读取数据;
- 调用 write 系统调用往目标文件写数据;
|
|
直接执行系统调用绕过标准 I/O 库,少了一次用户空间缓存和数据拷贝,理论上应该是最快的了,为啥还是比系统自带的 cat 命令慢一倍呢?我们先来解开 cat 命令背后的秘密。
首先,执行 strace 命令跑一下 cat 命令,跟踪看它是执行哪些系统调用的:
|
|
我们看到,系统自带的 cat 命令也是 read/write 等系统调用:
...
openat(AT_FDCWD, "cat.c", O_RDONLY) = 3
...
mmap(NULL, 1056768, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f341aed6000
read(3, "#include <errno.h>\n#include <fcn"..., 1048576) = 750
write(1, "#include <errno.h>\n#include <fcn"..., 750) = 750
read(3, "", 1048576) = 0
munmap(0x7f341aed6000, 1056768) = 0
close(3) = 0
- 调用 openat 打开文件;
- 循环读写:
- 调用 read 系统调用读取数据;
- 调用 write 系统调用写数据;
廖同学的程序跟系统自带的 cat 命令基本上一样的,耗时为啥会相差一倍呢?
我们注意到,系统 cat 命令在读写时使用的缓冲区大小是 1M ,而廖同学的是 4K 。换句话讲,系统 cat 命令每次读写的数据量更大,因此更快。《Unix环境高级编程》第 3.9 节 I/O 效率详细讨论了缓冲区大小对性能的影响,有兴趣的同学可以瞅瞅。
文件系统缓存
注意到,我生成 10g.bin 文件的同时,操作系统将文件数据缓存在 cache 中,因为 cache 内存暴增。文件数据缓存在内存中,读操作可以直接从内存中取数据,不用等待磁盘读取数据,效率更高。
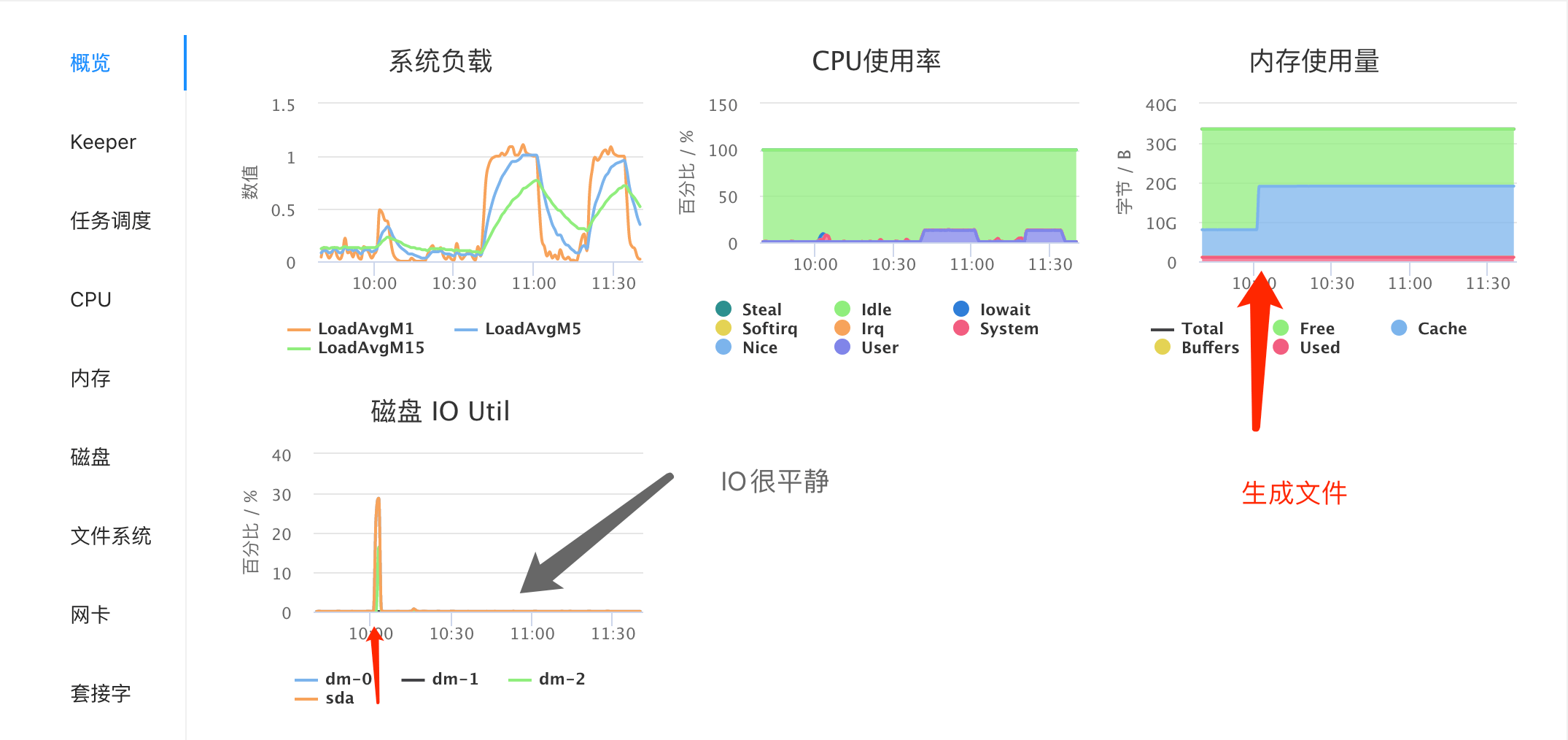
请看性能图表,跑压测时磁盘 IO 非常瓶颈,正是得益于缓存。生成文件过程中,磁盘 IO 有一个峰值,这就是将数据写入磁盘导致的。
让程序飞
像 cat 这种 I/O 型程序,核心操作就是数据拷贝,控制好数据拷贝,性能就能飞起。
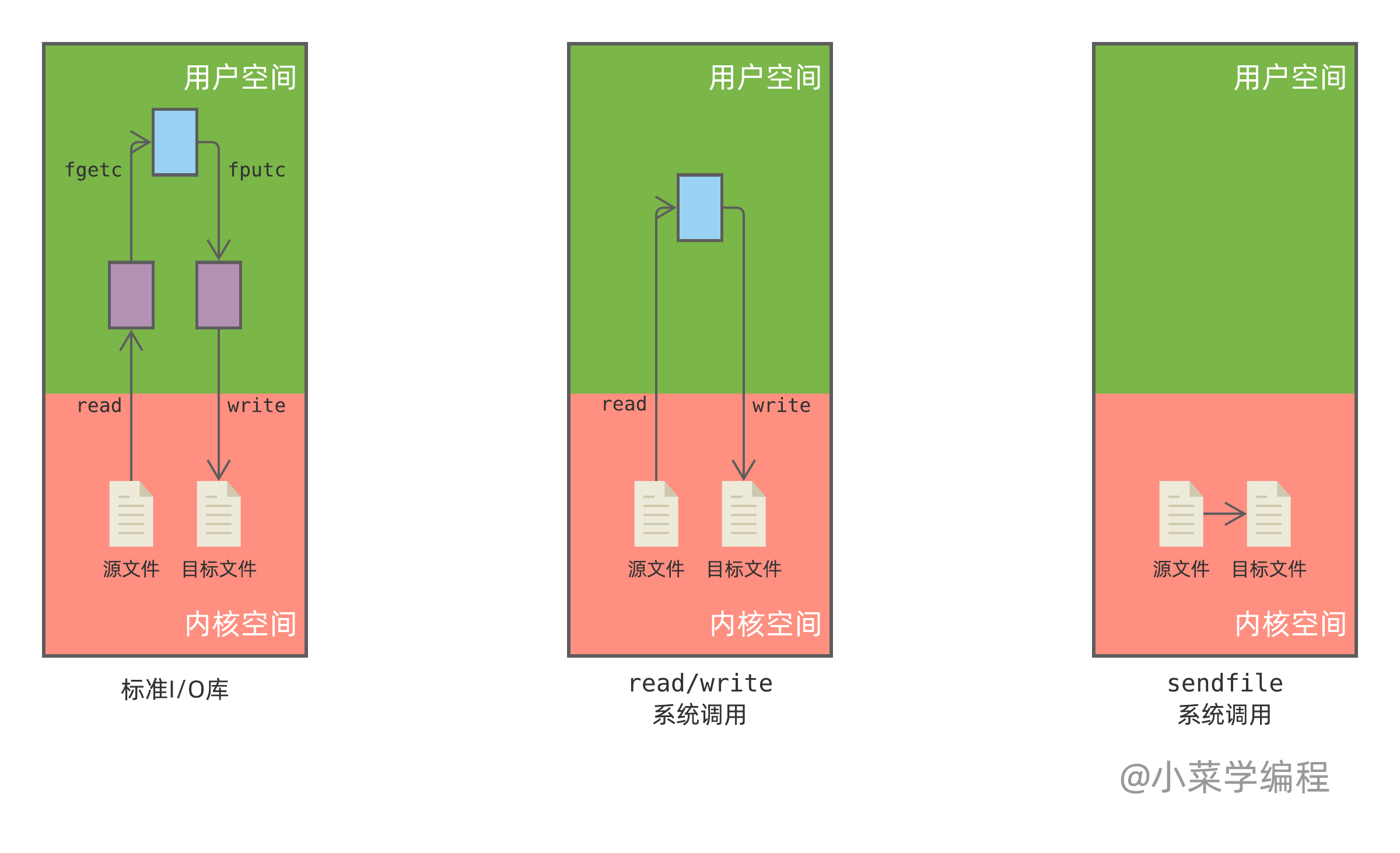
如果是调用标准 I/O 库,文件数据从内核空间读取到用户空间,需要经过两次数据拷贝。以读操作为例:
- 标准 I/O 库执行 read 系统调用,将文件数据从内核空间拷贝到自己在用户空间的缓冲区(紫色);
- 应用程序将数据从标准 I/O 库拷贝到自己的缓冲区(蓝色);
如果绕开标准 I/O 库,直接调 read/write 系统调用,数据不用在紫色缓冲区中转,拷贝次数节省一次。尽管如此,数据还是需要从内核拷贝到进程用户空间,然后再拷贝到内核。那么,有没有办法可以将这个拷贝也优化点呢?
当然有啦,这就是 sendfile 系统调用!执行这个系统调用,可以让内核在后端将源文件数据拷贝到目标文件,不用经过用户空间中转,效率极高!sendfile 系统调用需要 4 个参数,分别是:
- out_fd ,输出文件描述符(目标文件);
- in_fd ,输入文件描述符(源文件);
- offset ,开始拷贝的偏移量;
- count ,拷贝字节数;
我写了个程序测了一下,只需 0.05 秒!
|
|
注意到,开始拷贝偏移量设为零表示从头拷贝源文件;拷贝字节数设置成 size_t 类型的最大值,因为我不想管文件当前大小,反正内核会一直帮我拷贝,直到 EOF 。
既然 sendfile 系统调用效率这么好,为啥 cat 命令不用呢?原因是 sendfile 系统调用不太通用,不支持 管道( pipe )特殊文件等特殊文件,read/write 系统调用适应性更好。
sendfile 作为 Linux 零拷贝( zero-copy )技术的一种,常用于在网络程序中处理 套接字( socket ),后续有机会我在深入介绍一下。
《Unix环境高级编程》是后端工程师的必读经典,有兴趣也跟我们一起刷起来:
订阅更新,获取更多学习资料,请关注我们的公众号:

