 小菜学编程
小菜学编程

我们介绍过一个用几行 Shell 代码实现的简陋数据库,它的插入性能很好,但查询性能很差。
我们都知道,想要提升数据库的查询速度,索引必不可少 。那么,索引的底层结构都是怎样的呢?它们又是如何工作的呢?
实际上,数据库索引技术因底层数据结构不同,可以分为好几种:
- 哈希索引( hash index )
- LSM树( log structured merge tree )
- B树( b-tree )
其中,哈希索引的结构最为简单,但也很常用。今天我们就先将它一举拿下!
哈希索引结构
键值对存储引擎其实跟编程语言中的 字典 ( dictionary )类型很像,而字典底层通常是用 哈希表( hash table )实现的。既然哈希表可以用来索引内存中的数据,应该也可以用来索引磁盘数据吧?
我们实现的玩具数据库引擎,只是将数据记录源源不断地追加到数据文件。因此,只要在内存中维护一个哈希表,记录每个键最新记录在数据文件中的 偏移量( offset ),即可极大提升查询速度:
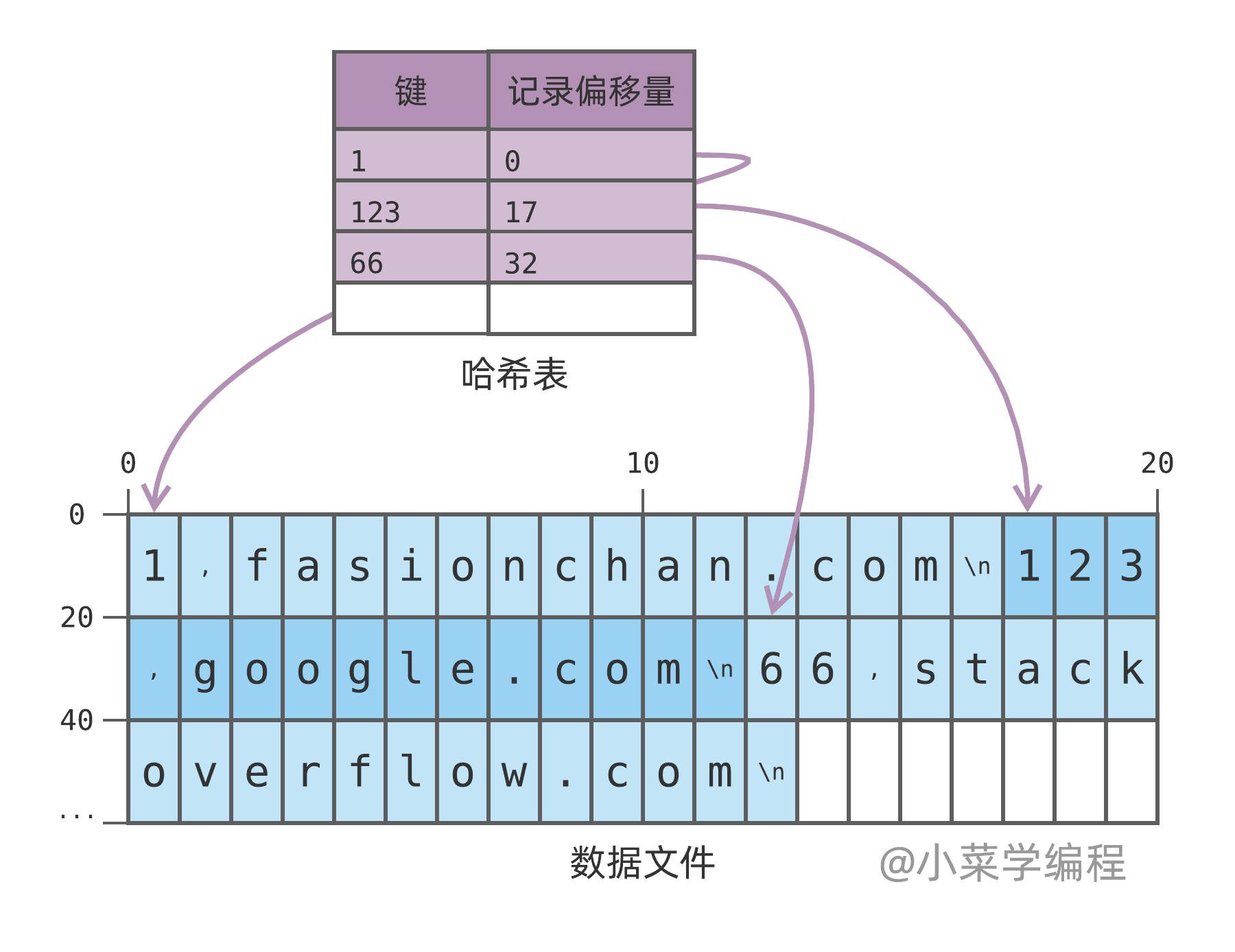
如上图,数据库当前保存着 3 个键值对记录:
1,fasionchan.com
123,google.com
66,stackoverflow.com
紫色部分是我们新引入的哈希表,它在内存中维护了每个键记录在文件中的最新偏移量。举个例子,键 123 最新记录的偏移量是 17 ,意味着 123 这条记录位于数据文件中的第 17 字节。
当我们查询键 123 时,数据库先从哈希表中找到数据记录的偏移量;然后再根据偏移量 seek 到文件指定位置,即可读出对应的数据,效率因而大大提升。
更新操作
当数据库处理插入或更新操作时,除了将数据记录追加到文件,还需要更新哈希表,以保存数据记录的最新偏移量。这就是索引给写操作带来的额外开销,好在哈希表操作通常都很快,这个开销是可控的。
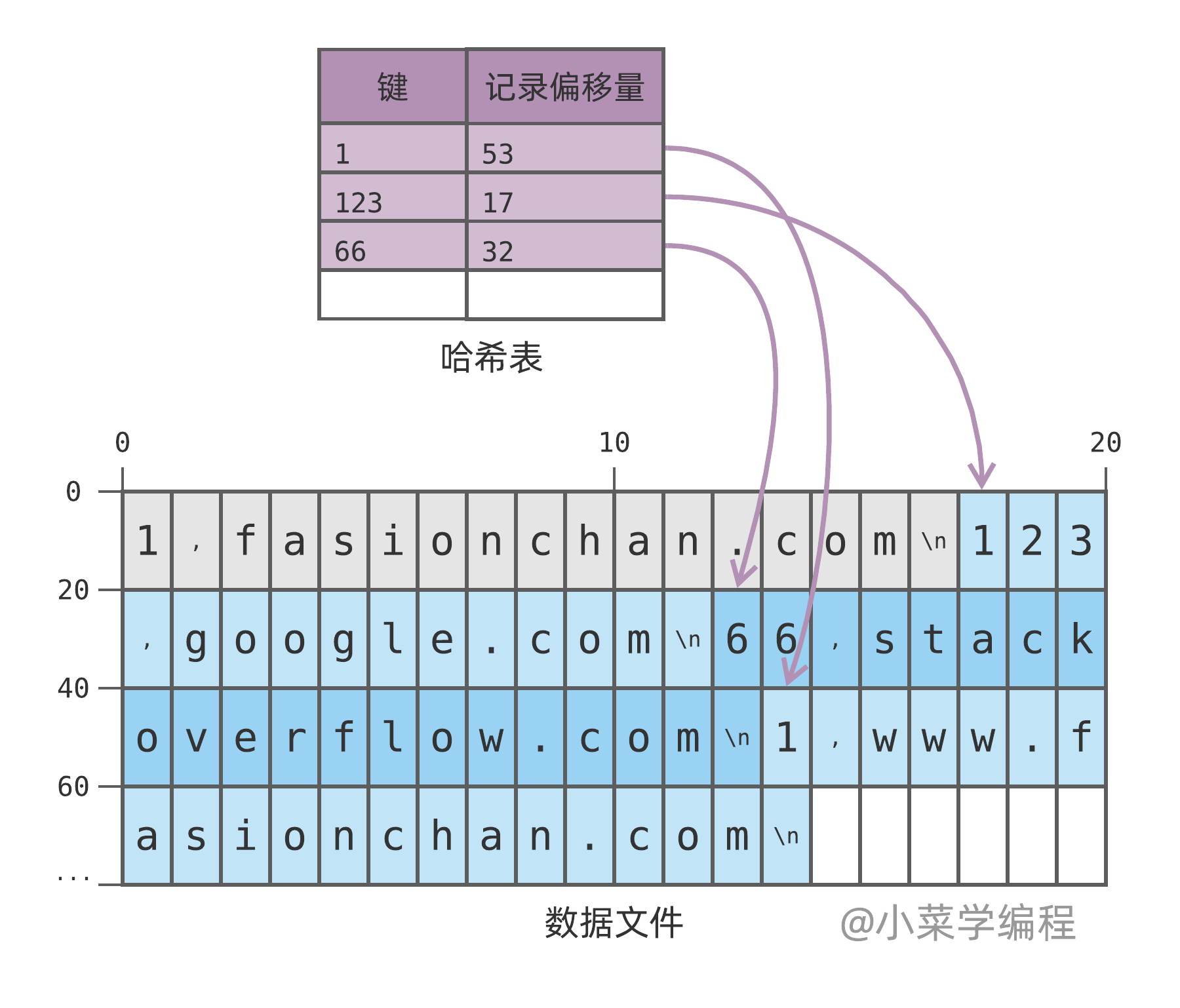
如上图,我们将键 1 的值改为 www.fasionchan.com ,数据库将新键值对记录追加到数据文件,偏移量为 53 。然后,它将哈希表中键 1 的偏移量更新为 53 ,指向最新的记录。
请注意,数据文件只会追加新记录,不会修改已有记录。更新操作也是通过追加新记录来实现的,新记录覆盖旧记录。如上图,灰色部分为键 1 的旧记录,现已失效。
删除操作
插入和更新都是往数据文件追加记录,那删除又该怎么办呢?
其实很简单,我们可以向数据文件追加一条特殊的记录,用来表示删除。例如,写入一条值为 4 个 \0 的记录,来删除键 123 :
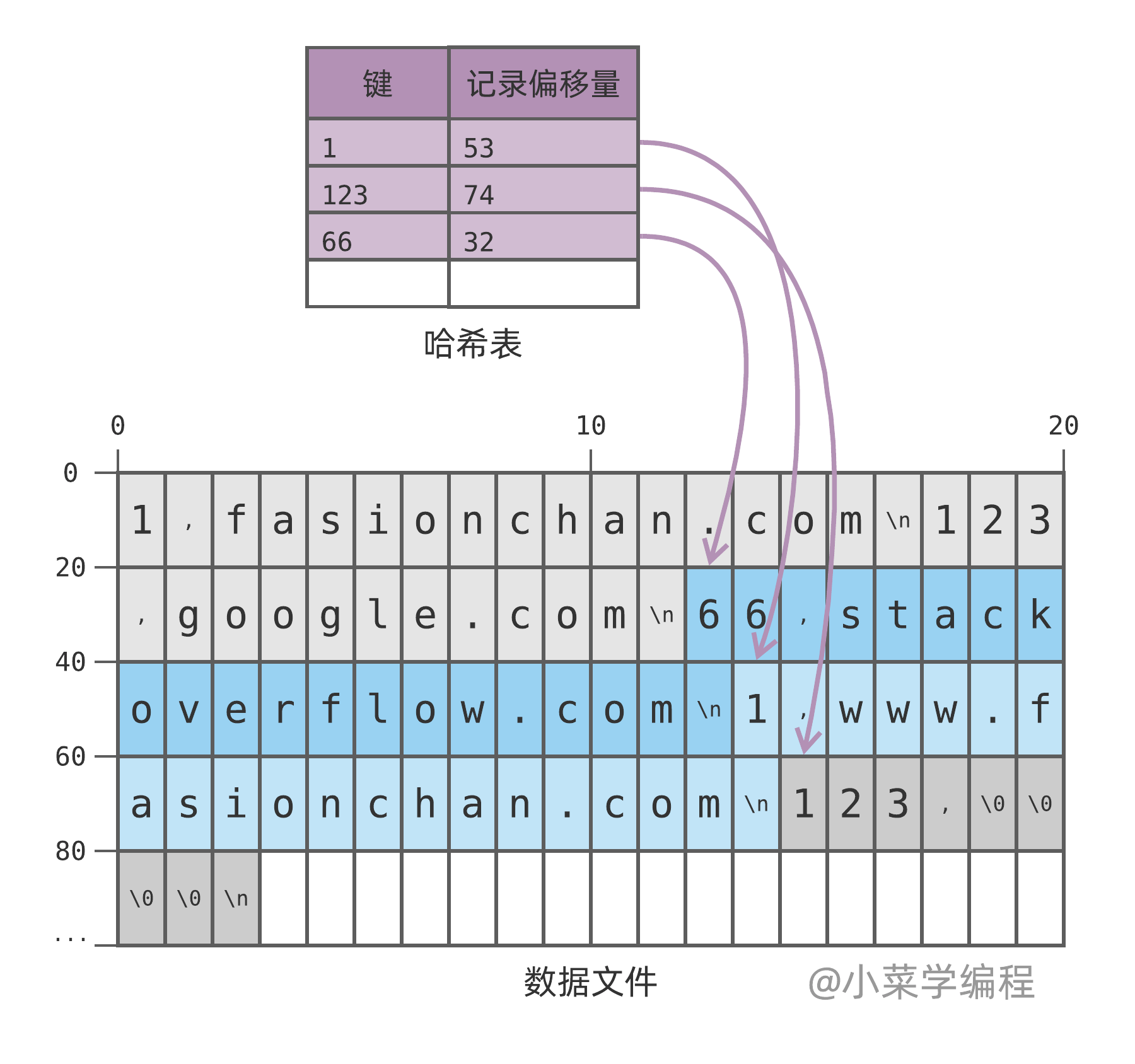
后续查询键 123 时,将得到特殊的删除标记 \0\0\0\0 ,便可知道该键已被删除。
内存开销
因为哈希表保存在内存里面,因此读写操作都非常快。但美中不足的是:内存必须能够容纳所有的记录键,否则就会成为瓶颈。而记录值就没有这个限制,因为它们只保存在磁盘文件中,就算远远超过物理内存也问题不大。
通过哈希表确定记录偏移量后,只需一次磁盘寻址,即可读到对应的记录值。如果文件系统刚好缓存了对应的磁盘数据块,那么可以直接从缓存读数据,连磁盘 IO 都省了。因此,就算数据值远远超出内存,查询效率也不会低。
磁盘空间回收
您可能会好奇,所有写操作都是往数据文件追加数据,永不删除,最后不会将磁盘写满吗?
随着时间推移,数据文件中无用部分(灰色)越来越多,有办法将这部分空间回收利用吗?
由于数据文件一直在追加写入,便难以回收其中的垃圾空间。但我们可以将数据文件分成多个片段:如果当前文件达到一定大小,就将它关闭,同时新建一个文件来写:
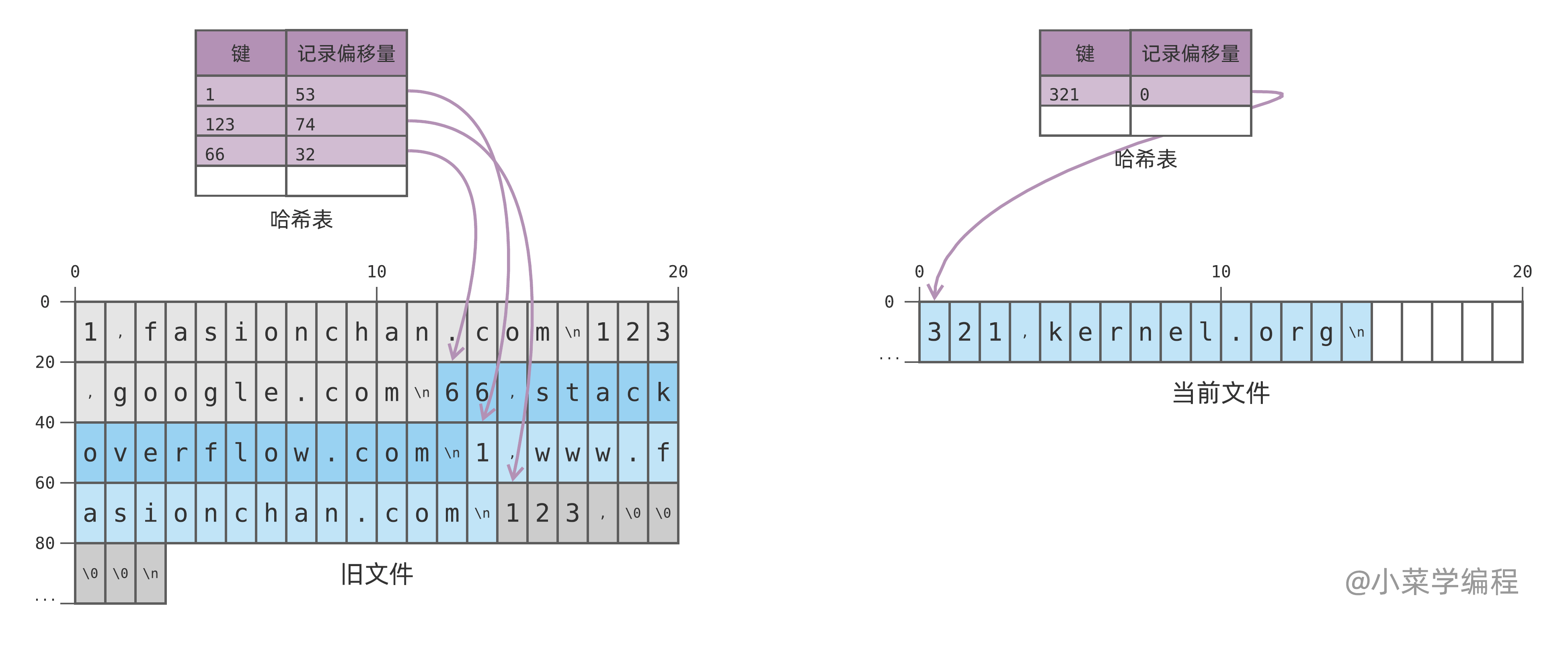
如上图,假设我们设定的阈值大小是 80 字节,如果这时再插入一个新数据 123 ,就要新开一个数据文件来写。注意到,每个分段文件都会维护自己的哈希表,查询时应该从最新文件开始,依次检索。
那么,将文件分段的好处是什么呢?
请注意,除了最新的数据文件还会追加数据外,旧的文件都不会再修改了。这样一来,我们就可以将旧的文件进行 精简( compaction ):将其中已经失效或者被删除的记录移除,最终只保留每个键的最新记录:
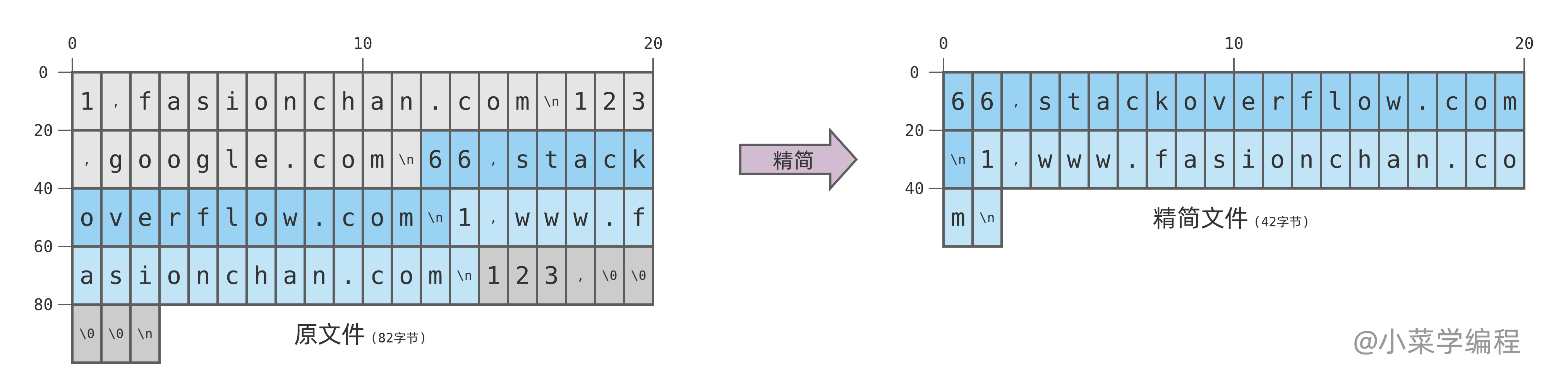
如上图,原文件中灰色部分为已失效的数据,深灰色部分为已被删除的数据,这两部分均可移除。注意到,源文件大小为 82 字节,经过精简后降为 42 字节,磁盘空间大大降低。
数据文件精简完毕后,即可替代原文件,而原文件则可安全移除。精简操作可以用后台线程来做,这时查询操作仍可检索原文件,完全不受影响。一旦精简完毕,可以将查询立马切换到精简后的文件上。
注意到,文件精简后数据记录偏移量肯定会有变动,因此哈希表也需要重建。
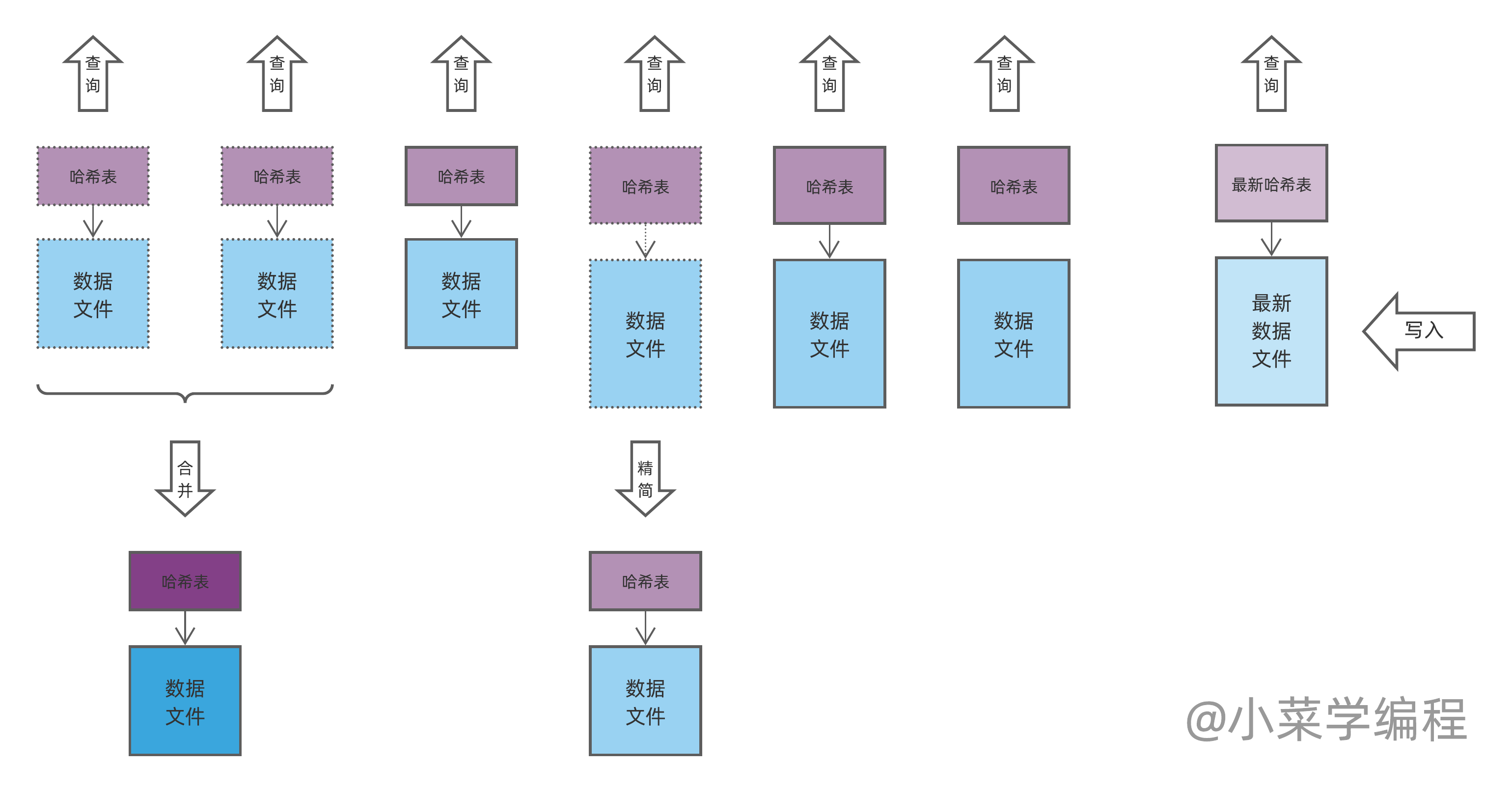
随着数据分段文件越来越多,查询需要遍历的文件也会越来越多,效率肯定越来越差。注意到,一个数据文件经过精简后,尺寸将大大减小。因此,我们可以将多个分段文件 合并( merge )为一个更大的分段文件:
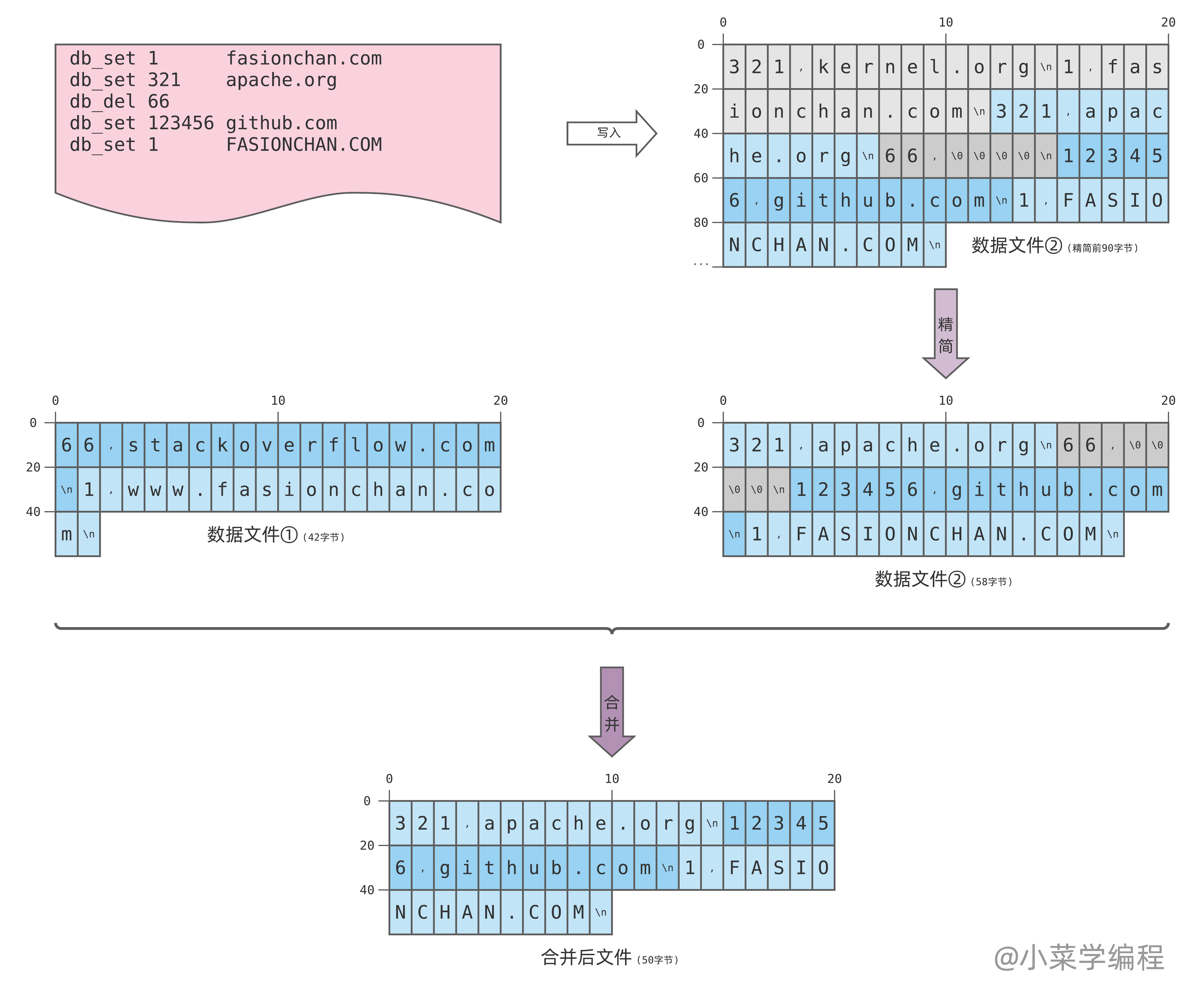
经过若干写操作,数据文件②也达到尺寸阈值,进而发生切换。切换完毕后,数据文件②就不再修改,可以在后台对其进行精简。请注意,对于键 66 的删除记录必须保留,因为更早的数据文件①中可能还有这个键。
于此同时,数据库可以在后台将精简过的两个数据文件进行合并。在合并过程中,键相同的记录将被进一步精简,只保留最新的一条。这样不仅进一步降低了磁盘使用量,也收敛了文件数量,查询效率因而能够得到保证。
注意到,键 66 在文件①中的老记录可被移除;其在文件②中的删除记录也可移除,因为所有 66 的历史记录均已移除。同样,合并操作可以用后台线程来做,合并完毕后再整体切换。
索引重建
您可能又有疑问了:哈希索引只保存在内存里面,数据库一宕机不就全没了吗?
的确如此。不过数据库重新启动后,可以根据每个分段文件中的数据,重新恢复索引。但恢复索引的过程需要遍历所有数据,如果数据量太大的话,肯定会比较耗时。
好在数据文件切换后,旧分段文件就不会再追加数据,而对应的哈希表也就固定不变了。如果这时将哈希表持久化到磁盘,故障重启时就可以直接从磁盘恢复哈希表,而不用再重建。这样一来,重启速度将大大加快。
由于最新的分段文件还会不断写入数据,它的哈希表仍会不断更新。由于哈希表更新基本上都是随机的,难以实时持久化到磁盘。不过没关系,故障恢复时我们只需重建最新分段的索引,耗时也相对可控。
总结
- 哈希索引擅长键值对存储场景;
- 磁盘擅长顺序写,数据文件总是在末尾追加写入;
- 更新操作也是在数据文件末尾追加新记录;
- 删除操作则是在数据文件末尾追加特殊的标记记录;
- 当数据文件超过一定大小,就新开文件来写;
- 只有最新的数据文件会写数据;
- 历史文件永远不会再写入数据;
- 查询时需要从最新文件开始,逐一检索;
- 为加快检索速度,每个文件都在内存中维护一个哈希索引;
- 哈希索引记录一个键在文件中的最新记录的偏移量;
- 哈希表保存在内存中,要求内存至少能够容纳所有键;
- 由于更新和删除操作,数据文件会有失效的记录;
- 对不再写入数据的历史文件进行精简,移除失效记录,即可回收磁盘空间;
- 对多个精简后的文件进行合并,既能进一步精简瘦身,又能降低文件数量,进而保证查询速度;
- 哈希索引保存在内存中,数据库故障就会丢失,但可以通过数据文件重建;
- 历史文件哈希表固定不变,可以将其持久化到硬盘,以加快故障恢复速度;
了解哈希索引底层原理后,我们知道它比较适用于键值对存储场景。
那 LSM树 和 B树 索引又是如何工作的呢?又适用于什么场景呢?因时间关系,等以后再一一介绍。心急的话可以先看看《数据密集型应用系统设计》,里面有详细介绍。偷偷说一句,本文也是参考这本书中的内容来写的,哈哈~
《数据密集型应用系统设计》是后端必读经典之一,作者涵盖了数据存储和分布式系统设计的方方面面,而且写得非常通俗易懂,强烈推荐!感兴趣可以在这看看目录:
订阅更新,获取更多学习资料,请关注我们的公众号:

