 小菜学编程
小菜学编程

上次我们分享了采用哈希索引实现的存储引擎,它总是将写操作不断追加到数据文件,就跟写日志一样。这种日志结构式的存储引擎,数据记录顺序由写入时间决定,同一键的旧记录由新记录取代。
SSTable
由于数据在写入时,自动切分成一个个文件。数据库需要在后台对文件进行合并,以减少文件数,进而加快查询。如果待合并文件里的数据是有序的,我们就可以采用归并排序算法来提高合并效率。
虽然这看起来会违背顺序写的原则,但也有办法解决,我们稍后介绍。
现在,我们将数据文件格式改成这样:①文件中的所有记录,按照 键( key )来排序;②排序保证了每个键只在文件中出现一次,不会有重复的旧记录。姑且将这种格式叫做 排序字符串表( sorted string table )简称 SSTable 。
相比普通日志结构式的数据文件,SSTable 有几个明显优势:
高效合并
如果您学过归并排序算法,应该知道合并两个有序序列是一个 既简单又高效 的操作:
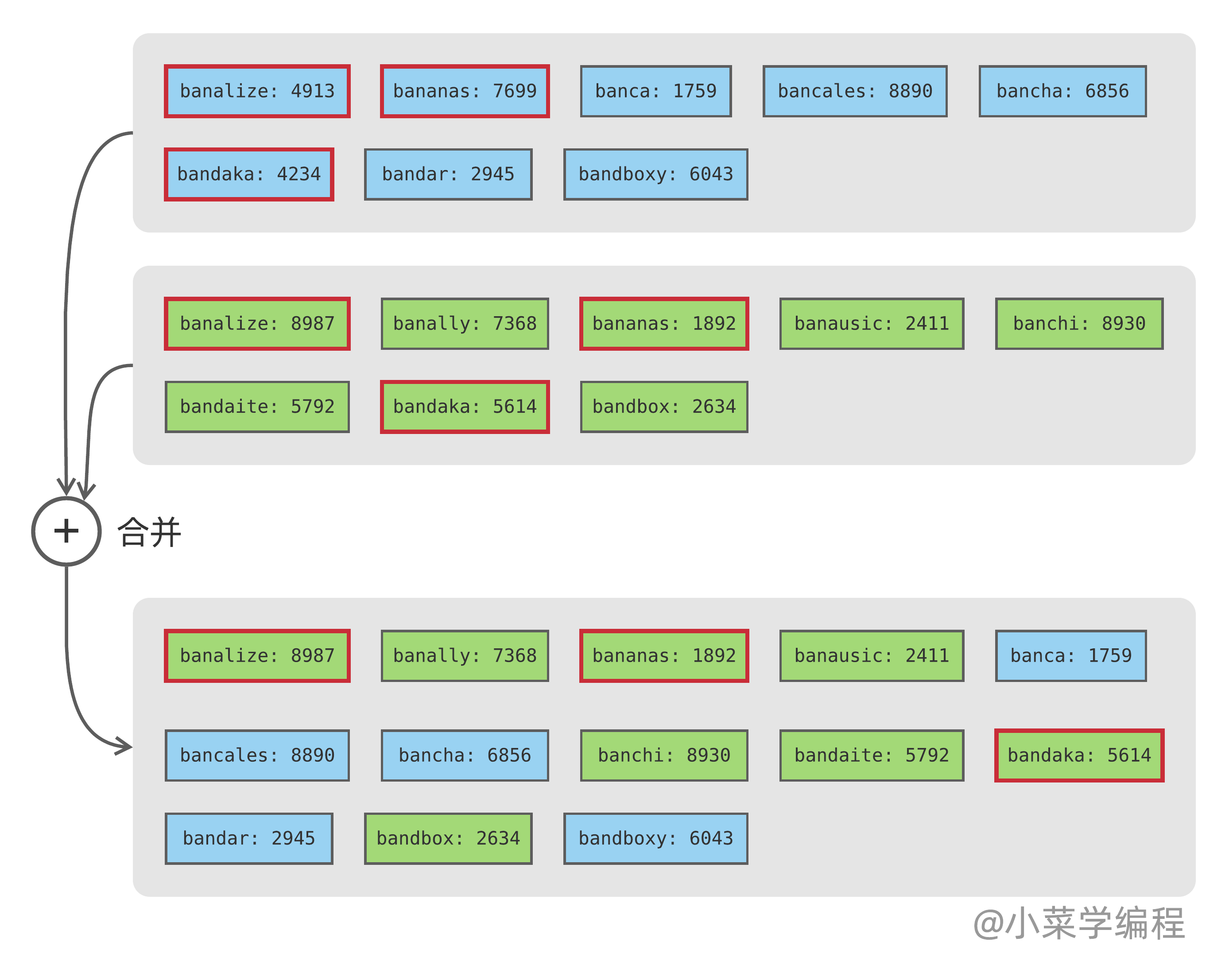
逐个遍历待合并文件,将最小的键拷贝到输出文件即可。如果同一个键在多个文件中出现,则以写入时间比较新的记录为准,其他均可丢弃。合并后得到的 SSTable 文件,数据也是按键排好顺序的,而且重复键均已去重。
SSTable 文件保存某段时间内写入的数据,一个 SSTable 数据跟另一个比较,要么较新,要么较旧。因此可以用这个特性进行去重,重复键以较新的 SSTable 为准。
合并时则必须保证 SSTable 是相邻的,否则就乱套了。假设有三个 SSTable ,按时段依次是 A 、B 、C ,其中 C 最新。如果先将 A 和 C 合并得到 X ,就无法再跟 B 合并了。因为 X 中的数据有的来自 A ,有的来自 C ,不好判断是比 C 新还是比 C 旧。
合并操作非常高效,算法时间复杂度是 $O(n)$ ,基本等同于将数据从源文件拷贝到目标文件即可。
读取待合并文件时是 顺序读 ,写结果文件时又是 顺序写 ,对磁盘非常友好。文件系统可以先预读待合并数据,然后缓存起来;又可以收集待写入数据,然后再批量写;磁盘 IO 操作便显著减少。
合并过程对内存要求极低,就算文件远远大于可用的物理内存也毫不碍事。
稀疏索引
您可能会这么想,既然 SSTable 数据是有序的,查询时是否可以用 二分查找法 进行搜索呢?
虽然二分查找法的时间复杂度是 $O(\log{}{N})$ ,但对磁盘操作来说还不够好。由于磁盘非常慢,IO 操作应该尽可能地减少,最好是只执行一次 IO 就能拿到数据。但二分查找需要执行 $O(\log{}{N})$ 次 IO 操作,而且每次读取的位置都不一样,对磁盘很不友好。
既然不能用二分查找法直接搜索磁盘数据,那就只能在内存中维护数据索引了。
由于磁盘中的 SSTable 是按键排序的,我们可以采用 排序树(比如红黑树)来组织索引,这样可以支持范围查询。举个例子,查询键在 A 和 B 之间的数据,可以先通过排序树索引,找到第一个大于等于 A 的数据的偏移量;再从该位置开始逐个读取,直到数据键大于 B 。
实际上,内存索引没有必要包含全部的键,每隔一定距离挑一个键即可:
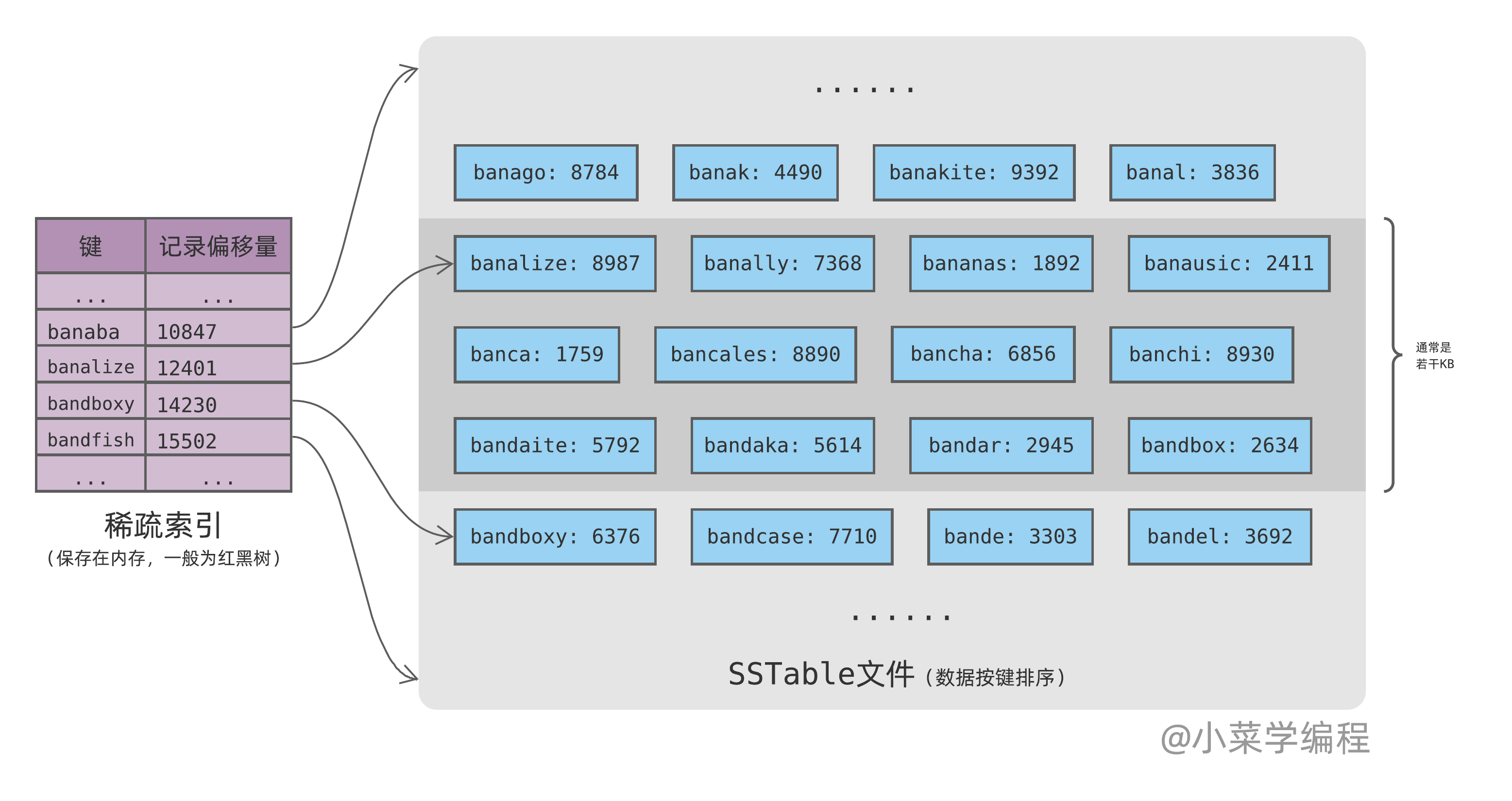
如上图,索引只包含部分键,大概呈均匀分布。当我们查询 bananas 时,我们查找内存中的索引,并没有找到该键。尽管如此,我们可以确定 bananas 落在 banalize 和 bandboxy 这两个键之间。
因此,只要从 banalize 键偏移量开始,不断遍历数据即可。如果当前 SSTable 包含 bananas ,那我们遍历少量数据后即可找到;如果不包含 bananas ,我们遍历到第一个比 bananas 大的键后即可停止。
稀疏索引一般每隔若干 KB 数据才维护一个索引项,内存使用量大大降低,但查询时却要读取更多数据。
好在磁盘数据是按块读取的,就算数据不够一个块,也得整块读取;而且由于磁盘寻址的因素,读一块和若干块的时间差别其实很小。因此,就算查询时需要多读一些数据,对性能也不会产生太大的负面影响。
节省磁盘带宽
由于查询时可能需要扫描两个索引项之间的全部数据记录(如上图阴影部分),因此可以将它们组织成逻辑数据块,压缩 之后再写到磁盘,索引条目则指向每个压缩块的开头。
由于相邻数据条目通常比较相像,至少他们的键都有相同的前缀,因此压缩后的尺寸能显著降低。这一方面节约了磁盘空间,另一方面则降低了磁盘 IO 带宽。
虽然压缩、解压缩需要消耗一定的 CPU 资源,好在 CPU 通常不是存储系统的主要瓶颈,磁盘 IO 才是。
因此,压缩这是一种典型的以时间换空间的技术选择,通过牺牲 CPU 资源来缓解带宽资源。在 Web 领域,服务器也经常对数据进行压缩,以节约带宽资源,缩短传输时间。
LSM树
SSTable 查询表现不错,但数据库写操作肯定是乱序的,怎样才能将数据排序保存呢?
在磁盘中维护排序结构倒也可行,B树( b-tree )就可以做到,但太复杂了。
如果是在内存里,事情就简单多了。众所周知,我们有很多数据结构可供选择,比如 红黑树( red-black tree )和 AVL树 。这些数据结构在乱序插入的前提下,也能支持有序遍历。
这样一来,我们可以这么设计:
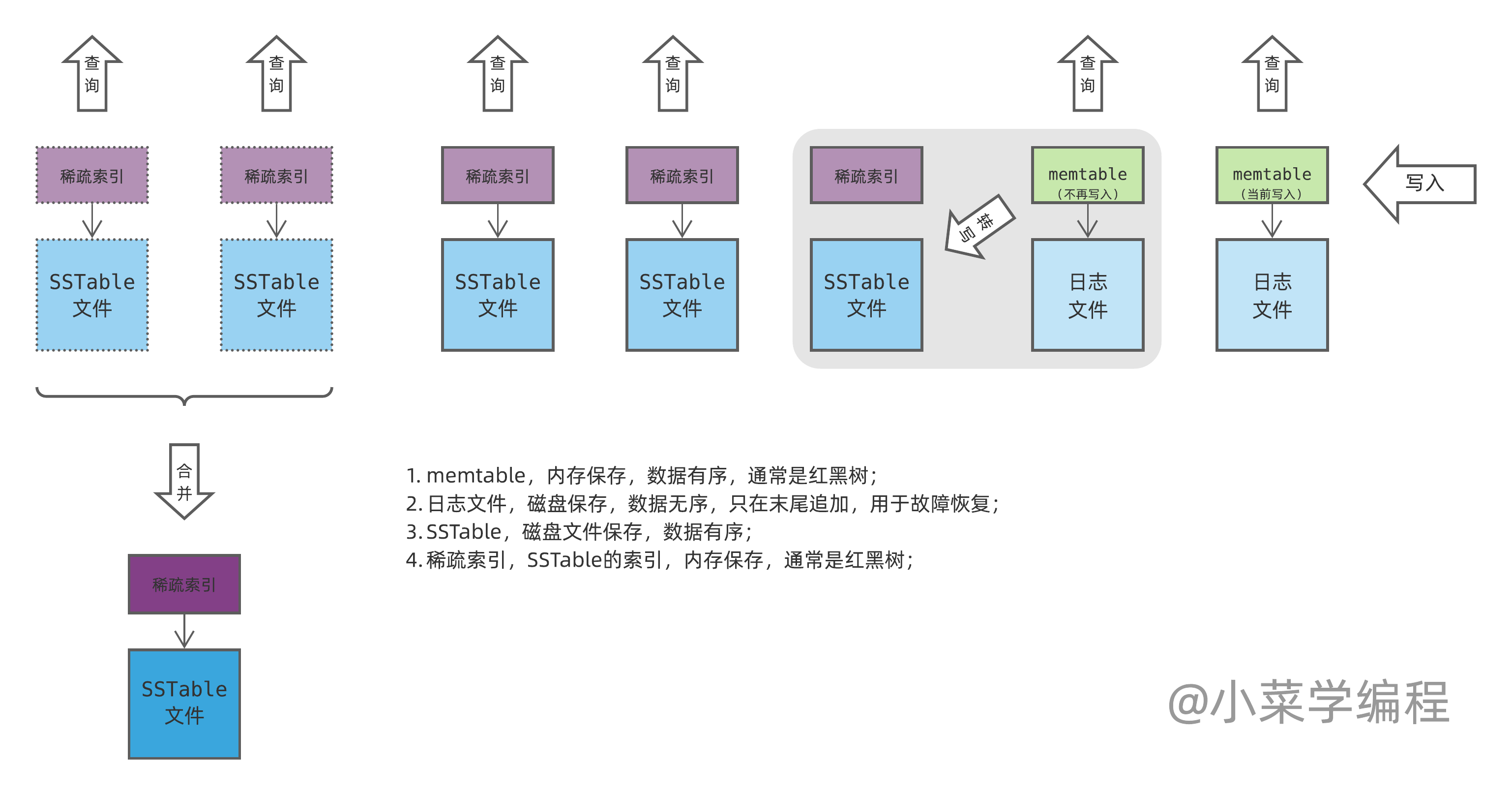
写操作到达后,将其保存到内存中的平衡树结构(比如红黑树)。这棵在内存中维护的平衡树称为 memtable 。
当 memtable 数据增长达到一定阈值(通常是若干 MB ),就将其转成 SSTable 文件并写到磁盘。由于 memtable 平衡树数据是按键排序,转写过程很高效——中序遍历数据并顺序写到磁盘即可。
虽然 memtable 转写效率很高,还是会阻塞数据库写操作,不管时间多短。为了不阻塞写操作,我们可以分配一个新的 memtable 来写,然后在后台慢慢转写旧的 memtable (如图阴影部分)。
那么,数据库读操作又该如何处理呢?您可能已经想到答案了:我们需要先查询 memtable ,然后再查询 SSTable 。再啰嗦一句, SSTable 必须从数据最新的那个开始,逐个查询。
那随着时间推移,SSTable 中应该会有不少被覆写或者删除的无效记录。这时,数据库可以在后台对 SSTable 进行合并,以去除无效记录,节约磁盘空间。于此同时,合并操作也可以减低 SSTable 个数,提高查询效率。
操作日志
这个方案看起来不错,但您可能也发现一个问题:如果数据库挂掉了,保存在 memtable 中的写操作不就丢了吗?
为了解决这个问题,我们可以在磁盘中维护一个日志文件,来记录写操作。每个写操作除了保存到 memtable 外,还要追加写到日志文件。这样就算 memtable 因故障丢失了,也可以通过重放日志文件来重建。
注意到,日志文件中的数据是按写入时间排序的,而不是按照数据键排序的。不过不要紧,因为日志文件只是为了故障时可以重建 memtable ,一旦 memtable 持久化到 SSTable,对应的日志文件就可以安全释放了。
查询优化
LSM树 查询一个不存在的键可能很慢,因为数据库要检查所有 SSTable ,才能确定待查键不存在。如果 SSTable 文件数量很多,查询效率肯定要大打折扣。
为了优化这类查询,数据库通常会额外维护一个 布隆过滤器 ( bloom filter )。这样一来,查询时先检查布隆过滤器,如果确定待查键不存在,就不必检查 memtable 和 SSTable 了。
布隆过滤器可以 大致 维护一个集合,而且非常节约内存。您可以将它当作一个特殊实现的集合,可以查询一个元素是否在集合内。大致 的意思是布隆过滤器可能会误判——查询存在而实际上不存在。但如果查询不存在,就一定是不存在的,不会误判。
总结
LSM树 索引擅长键值对存储场景,在 LevelDB 和 RocksDB 等数据库内部均有应用。它的设计思路很简单:
- 采用内存红黑树 memtable 保存最近写入的数据;
- 写 memtable 的同时,将操作日志写到磁盘,以便故障恢复;
- 定期将 memtable 数据刷到磁盘 SSTable ;
- SSTable 数据已经有序,配合稀疏索引,支撑高效查询;
至此,我们已经掌握了三种主流数据库索引技术中的两种,下节我们将继续聊 B树 索引。您若等不及,可以翻翻《数据密集型应用系统设计》一书,一睹为快!偷偷说一句,本文也是参考这本书中的内容来写的,哈哈~
订阅更新,获取更多学习资料,请关注我们的公众号:

