在 Python 中, 装饰器 一般用来修饰函数,实现公共功能,达到代码复用的目的。 在函数定义前加上 @xxxx ,然后函数就注入了某些功能,很神奇! 然而,这只是 语法糖 而已,起决定性作用的其实是前面介绍的 闭包 。
本文从最简单的场景入手,带你认识装饰器的前世今生。在洞悉装饰器运行机制的基础上,我们一起研究装饰器的若干高级技巧,你将大开眼界——原来代码可以这么写!掌握这些高级技巧之后,你将进一步强化代码抽象能力,用更精简的代码完成更复杂的处理逻辑,大幅提升开发效率。
场景
假设我们有一些工作函数,用来对数据进行不同的处理:
1
2
3
4
5
|
def work_bar(data):
pass
def work_foo(data):
pass
|
如果我们想在函数调用前后输出日志,该怎么办?
古典工艺
最直接的做法,是在函数调用前后加上打日志的语句:
1
2
3
|
logging.info('begin call work_bar')
work_bar(1)
logging.info('call work_bar done')
|
试想,如果程序中有多处 work_bar 函数调用会怎样呢?想想就怕!
函数封装
古典工艺比较原始,每次函数调用都要写一遍 logging ,引入太多代码冗余。我们知道,函数是程序逻辑封装和代码复用的基本单位。借助函数,我们可以把 logging 与函数调用作为一个整体封装起来复用,以此消除冗余:
1
2
3
4
|
def smart_work_bar(data):
logging.info('begin call: work_bar')
work_bar(data)
logging.info('call doen: work_bar')
|
这样一来,我们只需调用 smart_work_bar 即可:
1
2
3
4
5
|
smart_work_bar(some_data)
# others...
smart_work_bar(another_data)
|
通用闭包
函数封装方案看上去已经很科学了,但美中存在不足。举个例子,当 work_foo 调用前后也需要打日志时,我们还需要再实现一个新函数 smart_work_foo ,尽管它的功能与 smart_work_bar 并无二致!
我们观察发现, smart_work_bar 与 smart_work_foo 这两个函数的不同之处只是内部调用的函数不同。利用先前学到的 闭包 知识,我们实现 log_call 函数,将被调用函数参数化:
1
2
3
4
5
6
7
|
def log_call(func):
def proxy(*args, **kwargs):
logging.info('begin call: {name}'.format(name=func.__name__))
result = func(*args, **kwargs)
logging.info('call done: {name}'.format(name=func.__name__))
return result
return proxy
|
log_call 函数接收一个函数对象 func 作为参数,这是被代理函数;然后返回一个代理函数,即 proxy 函数。当代理函数 proxy 被调用时,先输出日志,然后调用被代理函数 func ,调用完毕后再输出日志,最后返回调用结果。 这样一来,不就达到通用化的目的了吗?——对于任意被代理函数 func , log_call 均可轻松应对。
1
2
3
4
5
6
7
8
9
10
|
smart_work_bar = log_call(work_bar)
smart_work_foo = log_call(work_foo)
smart_work_bar(some_data)
smart_work_foo(some_data)
# others...
smart_work_bar(another_data)
smart_work_foo(another_data)
|
第 1 行中, log_call 接收参数 work_bar ,返回一个代理函数 proxy ,并赋给 smart_work_bar 。 第 4 行中,调用 smart_work_bar ,也就是代理函数 proxy ;代理函数先输出日志,然后调用 func 也就是 work_bar ;最后再输出日志。 注意到,代理函数中, func 与传进去的 work_bar 对象紧紧关联在一起了,这就是 闭包 。
顺便提一下,可以覆盖被代理函数名,毕竟以 *smart_* 为前缀取新名字还是显得有些累赘:
1
2
3
4
5
|
work_bar = log_call(work_bar)
work_foo = log_call(work_foo)
work_bar(some_data)
work_foo(some_data)
|
语法糖
先回顾下面这段代码:
1
2
3
4
5
6
7
8
|
def work_bar(data):
pass
work_bar = log_call(work_bar)
def work_foo(data):
pass
work_foo = log_call(work_foo)
|
虽然代码没有什么冗余了,但是看是去还是不够直观。这时候,语法糖来了!
1
2
3
|
@log_call
def work_bar(data):
pass
|
请注意,开始 划重点啦 !你可以这样认为: @log_call 这行代码的作用只是告诉 Python 编译器,在函数定义后面插入代码 work_bar = log_call(work_bar) ,仅此而已。不信?我们拿字节码说话!
字节码
对上面这个装饰器版的 work_bar 函数代码进行编译,我们可以得到这样的字节码:
1
2
3
4
5
6
7
8
|
2 0 LOAD_NAME 0 (log_call)
2 LOAD_CONST 0 (<code object work_bar at 0x100cf2d20, file "<dis>", line 2>)
4 LOAD_CONST 1 ('work_bar')
6 MAKE_FUNCTION 0
8 CALL_FUNCTION 1
10 STORE_NAME 1 (work_bar)
12 LOAD_CONST 2 (None)
14 RETURN_VALUE
|
经过前面章节的学习,相信你对这些字节码已经非常熟悉了。接着,我们将虚拟机执行字节码的过程推演一番:
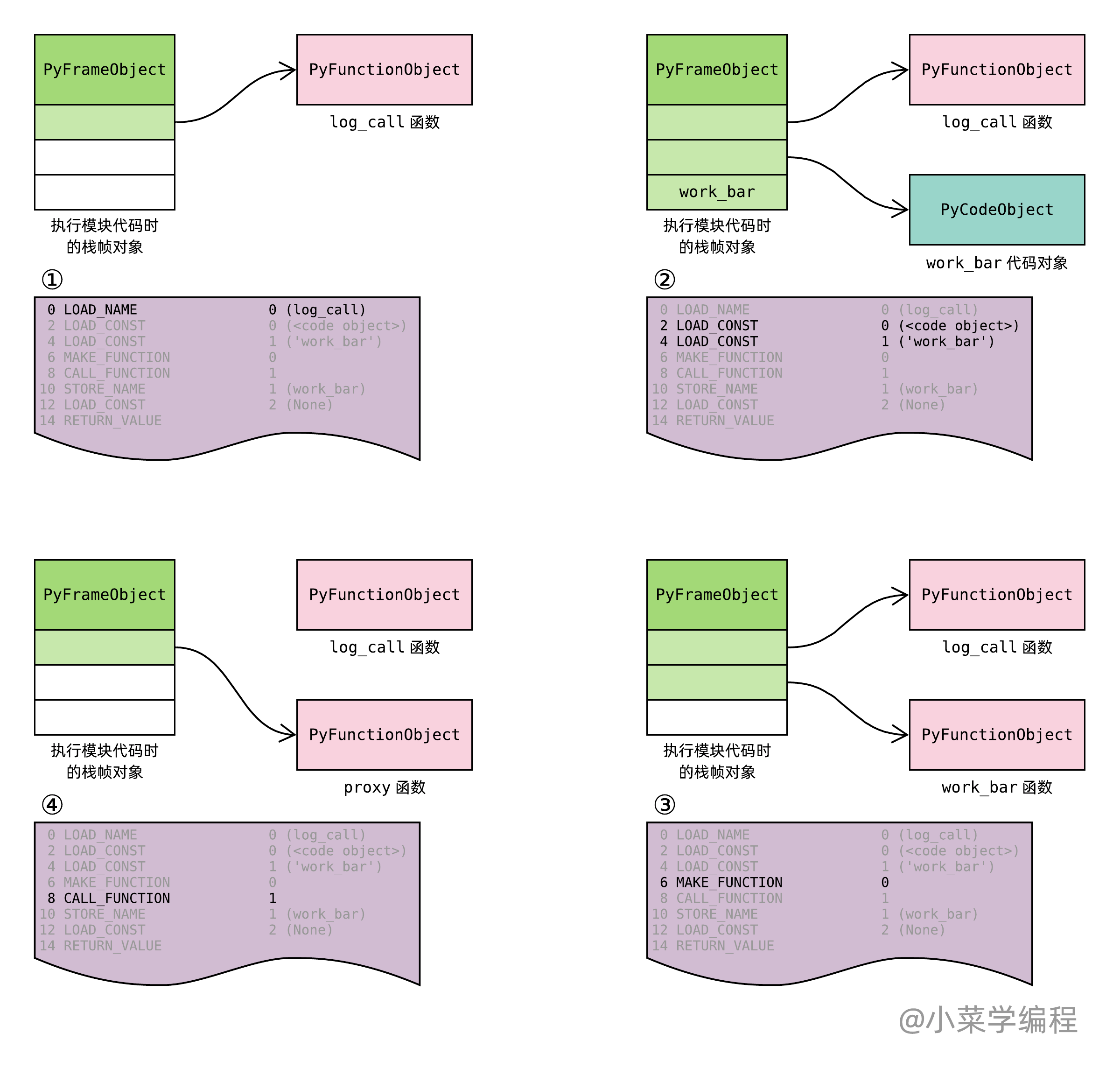
上图的字节码,你看懂了吗?求值装饰器、带参数装饰器和智能装饰器,又是如何提高我们的代码效率呢?点击“阅读原文”,获取更多详情!
- 第一条字节码将 log_call 函数加载进当前执行栈栈顶;
- 第二、三条字节码将 work_bar 代码对象和 work_bar 函数名加载到栈顶,为创建 work_bar 函数做好准备;
- 第四条字节码完成 work_bar 函数创建,该字节码执行完毕后,work_bar 函数便位于栈顶;
- 第五条字节码则以 work_bar 为参数调用 log_call 函数,并将 log_call 返回的 proxy 函数保存于栈顶;
- 接下来的 STORE_NAME 从栈顶取出 proxy 函数并保存到当前局部名字空间,它一般也是模块的属性空间;
这下明白了吧?以后面试官再聊装饰器时,总算不会心虚了!
求值装饰器
先来猜猜装饰器 eval_now 有什么作用?
1
2
|
def eval_now(func):
return func()
|
看上去好奇怪哦,装饰器内部没有定义代理函数,算装饰器吗?
1
2
3
4
5
6
|
>>> @eval_now
... def foo():
... return 1
...
>>> print(foo)
1
|
这段代码输出 1 ,也就是对函数进行调用求值。 那么,这种写法到底有什么用呢?直接写 foo = 1 不行么? 在这个简单的例子,这样写当然也是可以的。如果是更复杂的场景,就另当别论了。例如,初始化一个日志对象:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
# some other code before...
# log format
formatter = logging.Formatter(
'[%(asctime)s] %(process)5d %(levelname) 8s - %(message)s',
'%Y-%m-%d %H:%M:%S',
)
# stdout handler
stdout_handler = logging.StreamHandler(sys.stdout)
stdout_handler.setFormatter(formatter)
stdout_handler.setLevel(logging.DEBUG)
# stderr handler
stderr_handler = logging.StreamHandler(sys.stderr)
stderr_handler.setFormatter(formatter)
stderr_handler.setLevel(logging.ERROR)
# logger object
logger = logging.Logger(__name__)
logger.setLevel(logging.DEBUG)
logger.addHandler(stdout_handler)
logger.addHandler(stderr_handler)
# again some other code after...
|
借助 eval_now 装饰器,我们的 logger 对象还可以这样来写:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
# some other code before...
@eval_now
def logger():
# log format
formatter = logging.Formatter(
'[%(asctime)s] %(process)5d %(levelname) 8s - %(message)s',
'%Y-%m-%d %H:%M:%S',
)
# stdout handler
stdout_handler = logging.StreamHandler(sys.stdout)
stdout_handler.setFormatter(formatter)
stdout_handler.setLevel(logging.DEBUG)
# stderr handler
stderr_handler = logging.StreamHandler(sys.stderr)
stderr_handler.setFormatter(formatter)
stderr_handler.setLevel(logging.ERROR)
# logger object
logger = logging.Logger(__name__)
logger.setLevel(logging.DEBUG)
logger.addHandler(stdout_handler)
logger.addHandler(stderr_handler)
return logger
# again some other code after...
|
两段代码要达到的目的是一样的,但是后者显然更清晰,颇有独立 代码块 的风范。 更重要的是,日志对象在函数局部名字空间完成初始化,避免临时变量(如 formatter 等)污染外部的名字空间,特别是全局名字空间。
带参数装饰器
定义一个装饰器,用于记录慢函数调用:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
def log_slow_call(func):
def proxy(*args, **kwargs):
start_ts = time.time()
result = func(*args, **kwargs)
end_ts = time.time()
seconds = start_ts - end_ts
if seconds > 1:
logging.warn('slow call: {name} in {seconds}s'.format(
name=func.func_name,
seconds=seconds,
))
return result
return proxy
|
第 3 、 5 行分别在函数调用前后采样当前时间,第 7 行计算调用耗时,耗时大于一秒输出一条警告日志。
1
2
3
4
5
6
7
|
@log_slow_call
def sleep_seconds(seconds):
time.sleep(seconds)
sleep_seconds(0.1) # 没有日志输出
sleep_seconds(2) # 输出警告日志
|
然而,阈值设置总是要视情况决定,不同的函数可能会设置不同的值。如果阈值有办法参数化就好了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
def log_slow_call(func, threshold=1):
def proxy(*args, **kwargs):
start_ts = time.time()
result = func(*args, **kwargs)
end_ts = time.time()
seconds = start_ts - end_ts
if seconds > threshold:
logging.warn('slow call: {name} in {seconds}s'.format(
name=func.func_name,
seconds=seconds,
))
return result
return proxy
|
然而, @xxxx 语法糖总是以被装饰函数为参数调用装饰器。换句话讲,我们没机会来传递 threshold 参数。 这可怎么办呢?——只能再用一个闭包来封装 threshold 参数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
def log_slow_call(threshold=1):
def decorator(func):
def proxy(*args, **kwargs):
start_ts = time.time()
result = func(*args, **kwargs)
end_ts = time.time()
seconds = start_ts - end_ts
if seconds > threshold:
logging.warn('slow call: {name} in {seconds}s'.format(
name=func.func_name,
seconds=seconds,
))
return result
return proxy
return decorator
@log_slow_call(threshold=0.5)
def sleep_seconds(seconds):
time.sleep(seconds)
|
这样一来,调用 log_slow_call(threshold=0.5) 将返回 decorator 函数,该函数拥有闭包变量 threshold ,值为 0.5 。 decorator 再装饰 sleep_seconds 。
如果采用默认阈值,函数调用还是不能省略:
1
2
3
|
@log_slow_call()
def sleep_seconds(seconds):
time.sleep(seconds)
|
处女座可能会对第一行这对括号感到不爽,那么你还可以这样来改进:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
def log_slow_call(func=None, threshold=1):
def decorator(func):
def proxy(*args, **kwargs):
start_ts = time.time()
result = func(*args, **kwargs)
end_ts = time.time()
seconds = start_ts - end_ts
if seconds > threshold:
logging.warn('slow call: {name} in {seconds}s'.format(
name=func.func_name,
seconds=seconds,
))
return result
return proxy
if func is None:
return decorator
else:
return decorator(func)
|
这种写法兼容两种不同的用法,用法 A 默认阈值(无调用);用法 B 自定义阈值(有调用)。
1
2
3
4
5
6
7
8
9
10
|
# Case A
@log_slow_call
def sleep_seconds(seconds):
time.sleep(seconds)
# Case B
@log_slow_call(threshold=0.5)
def sleep_seconds(seconds):
time.sleep(seconds)
|
用法 A 中,发生的事情是 log_slow_call(sleep_seconds) ,也就是 func 参数是非空的,这时直接调 decorator 函数进行包装并返回,因此阈值是默认的。
用法 B 中,首先执行的是 log_slow_call(threshold=0.5) , func 参数为空,直接返回新的装饰器 decorator ,关联闭包变量 threshold ,值为 0.5 ; 然后, decorator 再装饰函数 sleep_seconds ,即执行 decorator(sleep_seconds) 。 注意到,此时 threshold 关联的值是 0.5 ,由此实现了阈值定制化。
你可能注意到了,这里最好使用关键字参数这种调用方式——使用位置参数会很丑陋:
1
2
3
4
|
# Case B-
@log_slow_call(None, 0.5)
def sleep_seconds(seconds):
time.sleep(seconds)
|
当然了, 函数调用尽量使用关键字参数 是一种极佳实践,含义清晰,在参数很多的情况下更应如此。
后来我又悟出另一种更加精炼的写法,亲你能否猜出?哈哈,我先卖个关子,答案在《面试题精讲》一节揭晓。
智能装饰器
上节介绍的带参数装饰器写法,嵌套层次较多。如果每个类似的装饰器都用这种方法实现,还是比较费劲的,也比较容易出错,脑子可能不够用呢。那么,有没有办法进一步进行优化呢?
假设,我们有一个智能装饰器 smart_decorator ,用来修饰装饰器 log_slow_call ,便使其具备参数化的能力。 这样, log_slow_call 定义将变得更清晰,实现起来也更省事了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
@smart_decorator
def log_slow_call(func, threshold=1):
def proxy(*args, **kwargs):
start_ts = time.time()
result = func(*args, **kwargs)
end_ts = time.time()
seconds = start_ts - end_ts
if seconds > threshold:
logging.warn('slow call: {name} in {seconds}s'.format(
name=func.func_name,
seconds=seconds,
))
return result
return proxy
|
脑洞开完, smart_decorator 如何实现呢?掌握闭包和装饰器的执行机制,这其实也简单:
1
2
3
4
5
6
7
8
9
10
11
12
|
def smart_decorator(decorator):
def decorator_proxy(func=None, **kwargs):
if func is not None:
return decorator(func=func, **kwargs)
def decorator_proxy(func):
return decorator(func=func, **kwargs)
return decorator_proxy
return decorator_proxy
|
smart_decorator 实现了以后,我们的设想就成立了! 这时, log_slow_call ,就是 decorator_proxy (外层), 关联的闭包变量 decorator 是本小节最开始定义的 log_slow_call (为了避免歧义,我们将其称为 real_log_slow_call )。由此一来, log_slow_call 支持以下各种用法:
1
2
3
4
|
# Case A
@log_slow_call
def sleep_seconds(seconds):
time.sleep(seconds)
|
用法 A 中,执行的是 decorator_proxy(sleep_seconds) (外层), func 非空, kwargs 为空; 直接执行 *decorator(func=func, *kwargs) ,即 real_log_slow_call(sleep_seconds) ,结果是关联默认参数的 proxy 。
1
2
3
4
5
|
# Case B
# Same to Case A
@log_slow_call()
def sleep_seconds(seconds):
time.sleep(seconds)
|
用法 B 中,先执行 decorator_proxy() , func 及 kwargs 均为空,返回 decorator_proxy 对象(内层); 再执行 decorator_proxy(sleep_seconds) (内层);最后执行 decorator(func, **kwargs) , 等价于 real_log_slow_call(sleep_seconds) ,效果与用法 A 一致。
1
2
3
4
|
# Case C
@log_slow_call(threshold=0.5)
def sleep_seconds(seconds):
time.sleep(seconds)
|
用法 C 中,先执行 decorator_proxy(threshold=0.5) , func 为空但 kwargs 非空,返回 decorator_proxy 对象(内层); 再执行 decorator_proxy(sleep_seconds) (内层);最后执行 decorator(sleep_seconds, **kwargs) , 等价于 real_log_slow_call(sleep_seconds, threshold=0.5) ,阈值实现自定义!
到底如何才能提升我的 Python 开发水平,向更高一级的岗位迈进呢?
如果你有这些问题或者疑惑,请订阅我们的专栏 Python源码深度剖析 ,阅读更多章节:

【Python源码剖析】系列文章首发于公众号【小菜学编程】,敬请关注:

 小菜学编程
小菜学编程
