SQL注入( SQL injection )是一种将恶意代码插入到程序 SQL 语句中,从而误导数据库执行恶意逻辑的攻击技术。通过 SQL 注入,攻击者可以达到获取敏感信息,窃取访问权限等目的。
因此,在设计数据库应用时,必须警惕 SQL 注入风险,并加以防范。
 小菜学编程
小菜学编程

SQL注入( SQL injection )是一种将恶意代码插入到程序 SQL 语句中,从而误导数据库执行恶意逻辑的攻击技术。通过 SQL 注入,攻击者可以达到获取敏感信息,窃取访问权限等目的。
因此,在设计数据库应用时,必须警惕 SQL 注入风险,并加以防范。
任何系统通常都有用户,数据库因而少不了用户表,少不了要保存用户密码。那么,密码能明文保存吗?肯定不能!
如果用户密码用明文保存,一旦数据库被拖库,用户密码就全泄露了呀!用户密码泄露可不是件小事,影响的也不仅仅是泄露站点,因为用户通常用同一个密码走天下!
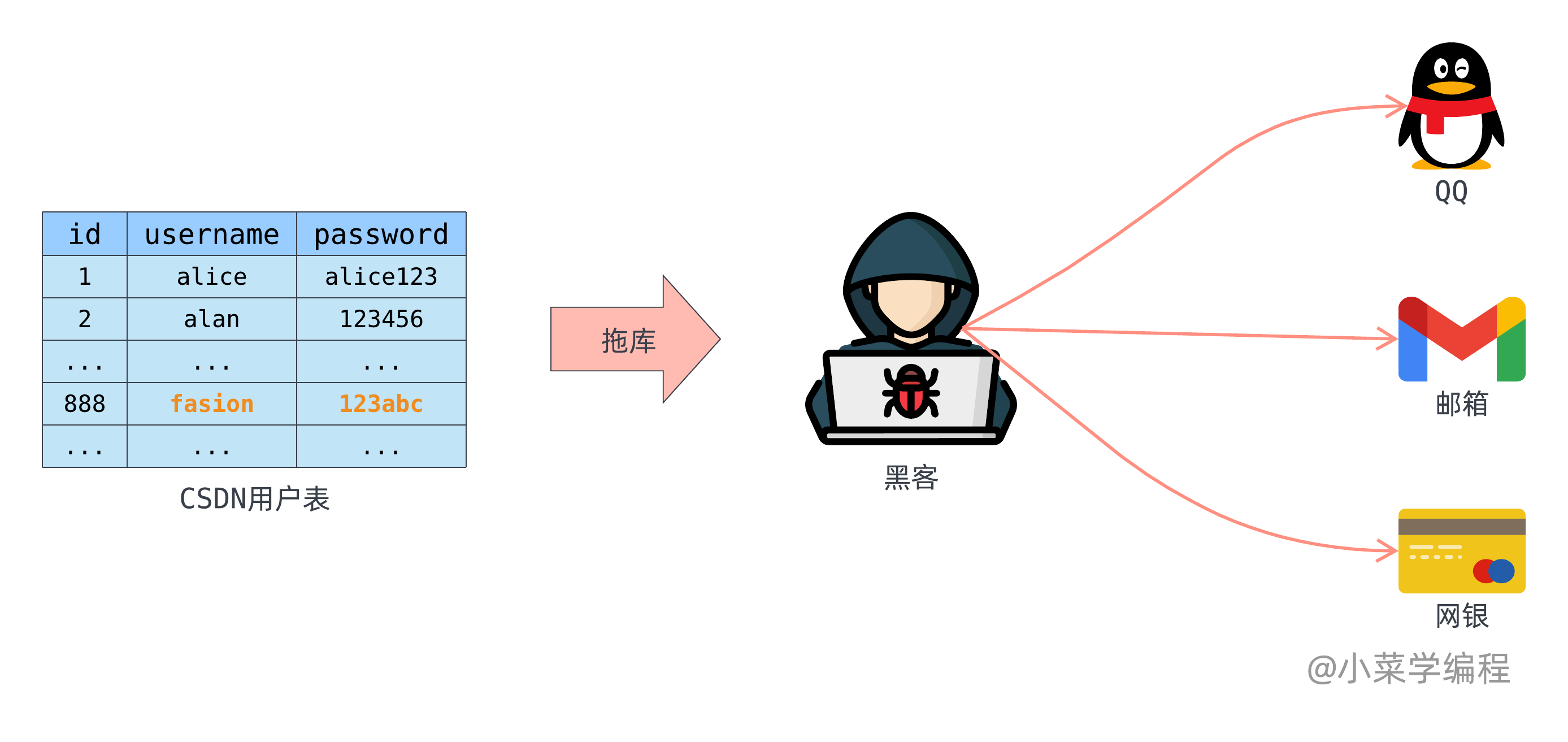
写到这不禁想起多年前发生的 CSDN 拖库事件,泄露了大量用户的密码,笔者的账号密码也在其中。顺便吐槽一下,CSDN 烂不是一天两天了,一个程序员交流网站竟然明文保存密码!
当年我还年轻,好多网站的账号密码都是一样的。黑客拖库得到我的账号密码后,可以用它来登录我的 QQ ,我的邮箱,甚至是网银!想想就觉得可怕!
在 4.0 版本之前,MongoDB 是不支持事务的,只能由应用程序自行保证事务性。本文以银行转账为例,讲解如何在不支持事务的 MongoDB 上实现转账事务。
客户账上余额由 accounts 表保存,表结构大致如下:
|
|
如果客户 A 发起一笔转账,转 10 元给 B ,那么余额表应该是这样的(假设没有其他操作):
|
|
由于转账需要同时修改两条账户记录,为保证数据一致性,我们必须保证:它们要么全都修改成功,要么全都保持初始原因,不能有中间状态。
这就是转账操作的事务性要求,那么我们应该如何实现这一点呢?
前面我们介绍了 哈希索引 和 LSM树索引 ,它们都基于日志结构式的数据文件。虽然工程界对这种索引的认可度正与日俱增,但还远不是最受欢迎的索引技术。
那么,目前应用最广的索引技术又是什么呢?
您可能早就有所耳闻——这就是本文要探讨的 B树( b-tree )索引。B树可以说是数据库索引技术中的武林盟主,能够几十年长盛不衰,必定有它自己的独门秘诀。
跟我们在 LSM树 一节中提到的 SSTable 一样,B树也是将数据组织成有序形式,因此支持范围查询。尽管如此,它们的底层结构却完全不同,B树有自己独特的设计哲学。
上次我们分享了采用哈希索引实现的存储引擎,它总是将写操作不断追加到数据文件,就跟写日志一样。这种日志结构式的存储引擎,数据记录顺序由写入时间决定,同一键的旧记录由新记录取代。
由于数据在写入时,自动切分成一个个文件。数据库需要在后台对文件进行合并,以减少文件数,进而加快查询。如果待合并文件里的数据是有序的,我们就可以采用归并排序算法来提高合并效率。
虽然这看起来会违背顺序写的原则,但也有办法解决,我们稍后介绍。
现在,我们将数据文件格式改成这样:①文件中的所有记录,按照 键( key )来排序;②排序保证了每个键只在文件中出现一次,不会有重复的旧记录。姑且将这种格式叫做 排序字符串表( sorted string table )简称 SSTable 。
我们介绍过一个用几行 Shell 代码实现的简陋数据库,它的插入性能很好,但查询性能很差。
我们都知道,想要提升数据库的查询速度,索引必不可少 。那么,索引的底层结构都是怎样的呢?它们又是如何工作的呢?
实际上,数据库索引技术因底层数据结构不同,可以分为好几种:
其中,哈希索引的结构最为简单,但也很常用。今天我们就先将它一举拿下!
键值对存储引擎其实跟编程语言中的 字典 ( dictionary )类型很像,而字典底层通常是用 哈希表( hash table )实现的。既然哈希表可以用来索引内存中的数据,应该也可以用来索引磁盘数据吧?
最近重读《数据密集型应用系统设计》这本书,看到第三章《数据存储与检索》,主要讲数据库内部的索引技术。
从本质上讲,数据库主要是做两件事情:
这两件事情看似简单,背后却暗含玄机。那么,数据库内部到底是如何存储数据的呢?又是如何检索数据的呢?
你可能会有这样的疑问:我作为一个开发人员,为什么需要知道数据库内部是怎么工作的呢?