 小菜学编程
小菜学编程

大端( Big endian )和 小端( Little Endian )是计算机存储 多字节 数据的两种不同方式。
定义
在 大端 系统,多字节数据类型 起始字节先存储 ;相反,在 小端 系统,多字节数据类型 末尾字节先存储 。
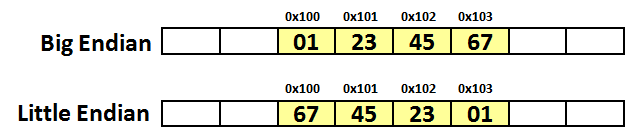
假设有一个 4 字节长整数变量 y ,值为 0x01234567 (十六进制表示法) 。在 大端 系统上,该变量保存为以下 4 个字节: 0x01 、 0x23 、 0x45 、以及 0x67 ;在 小端 系统上,存储顺序刚好相反:
辅助记忆
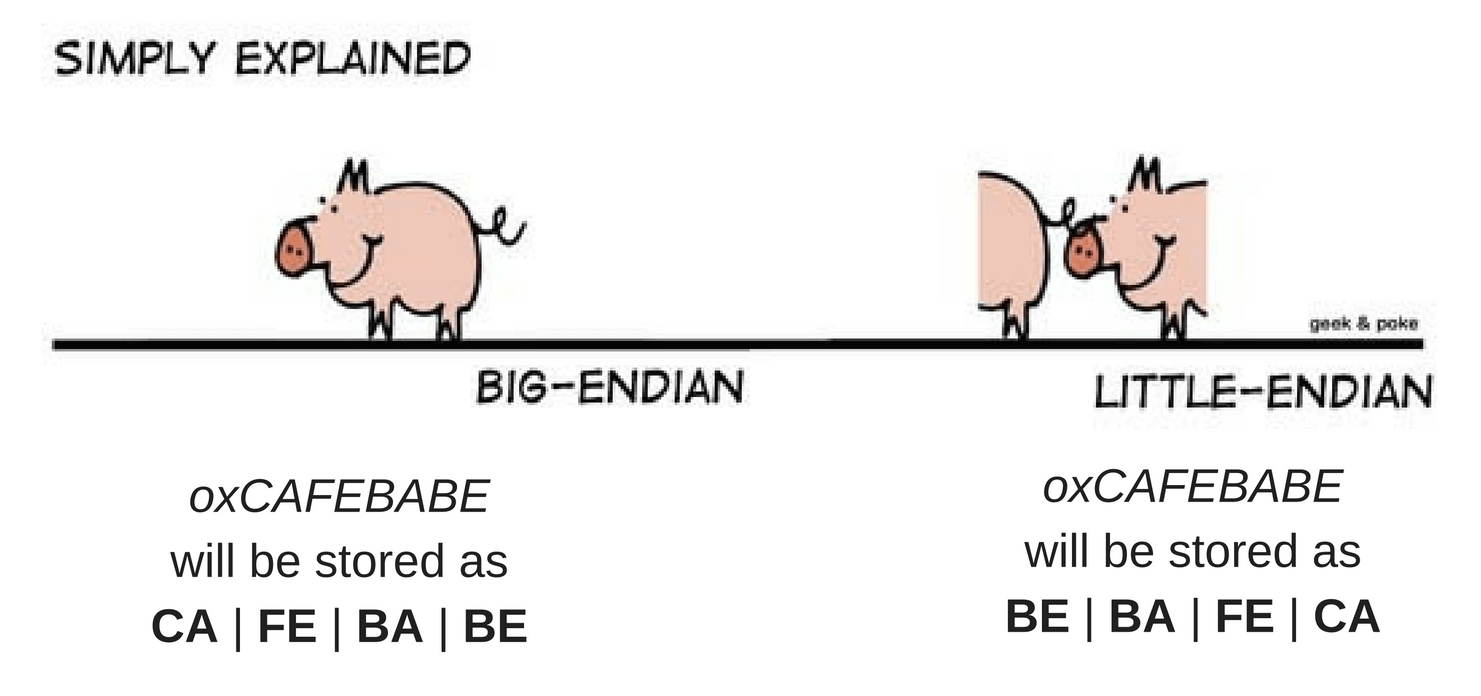
记忆大端小端定义很容易搞混,通过以下图形可以更好地记住,非常形象:
内存表现形式
如果需要查看多字节数据类型在 内存 中的表现形式, 可以遍历数据每个字节,以 十六进制 将字节打印出来。下面是一份示例代码:
|
|
字节序判断
如果无法人为确定当前系统字节序是大端还是小端,可以编写一个简单程序进行判断:
|
|
原理很好理解,定义一个整数,值为 1 ,然后判断其 第一个字节 的值。
网络字节序
不同字节序系统进行网络通信,不加以注意是要乱套的。
为了解决这个问题,约定进行网络通信时统一采用 大端 字节序。 因此, 大端 字节序也称为 网络字节序 。
封装网络报文时,需要在 主机字节序 和 网络字节序 之间转换。 C 库提供了转换函数(宏):
- htons ,将 短整数 (两字节)从 主机字节序 转成 网络字节序 ;
- htonl ,将 长整数 (四字节)从 主机字节序 转成 网络字节序 ;
- ntohs ,将 短整数 (两字节)从 网络字节序 转成 网络字节序 ;
- ntohl ,将 长整数 (四字节)从 网络字节序 转成 网络字节序 ;
举个例子,在填充地址结构体端口字段时,需要通过 htons 进行转换:
addr.sin_port = htons(80)
转换函数有 4 个之多,借助下表可以更好地记忆:
| 字母 | “含义” |
|---|---|
| h | 主机字节序 |
| n | 网络字节序 |
| s | 短整数(两字节) |
| l | 长整数(四字节) |
优缺点
这两种表示方式各有优缺点:
对于 小端 字节序,取不同长度整数的 汇编指令 处理方式相同:都是从第 0 字节开始。此外,由于地址 偏移量 与 字节 的关系一一对应, 多精度 数学例程很容易实现。
对于 大端 字节序,由于高位字节先存储,判断数字 正负 只需检查 第一个字节 (偏移量为 0 )。因此,无需跳过一些字节以定位包含 符号 的字节,也无需知晓 变量长度 。
【小菜学网络】系列文章首发于公众号【小菜学编程】,敬请关注:

