 小菜学编程
小菜学编程

掌握网络层基本工作原理后,是时候来认识网络层中的最重要的 IP 协议了。
IP 是 互联网协议 ( internet protocol ) 的简称,是 TCP/IP 协议栈中的网络层协议。IP 协议在发展的过程中,衍生出 IPv4 和 IPv6 两个不同版本。其中,历史版本 IPv4 目前仍广泛使用;后继版本 IPv6 世界各地正在积极部署。
IP 协议的通信单元是 IP 包 ( packet ),同样分为 IPv4 和 IPv6 两个版本,本节重点研究 IPv4 包结构。虽然我们对 IPv4 包结构仍一无所知,但经过网络层的学习,我们可以大致猜测一下:它应该分为头部和数据两大部分;其中头部应该包含源地址、目的地址以及数据类型等字段。
IPv4包
废话不多说,直接开门见山。一个 IPv4 包的结构是这样的:
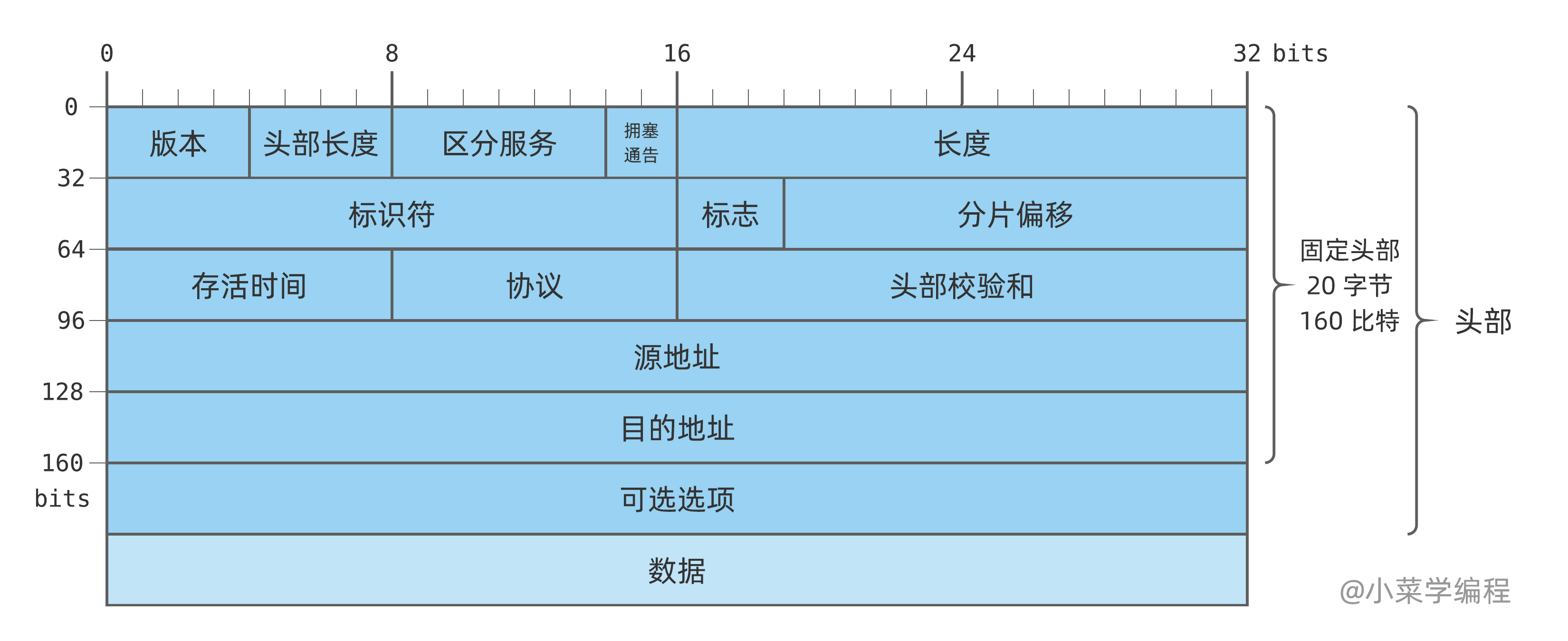
我们猜得没错,IP 包也分为 头部 ( header ) 和 数据 ( data )两大部分,其中头部也可称为 首部 。虽然我们猜到了头部中的几个关键字段,头部却远比我们想象中的要复杂。
接下来,我们简要介绍一下 IP 头部各个字段。一开始看得一头雾水也没有关系,先有个大概印象即可,具体细节后续章节还会展开介绍。
版本
IP 头部第一个字段是 版本 ( version ),它占用 4 个比特,位于 IP 包的最前面,也就是第一个字节的高 4 位。采用 IP 协议通信的双方,使用的版本必须一致。对于 IPv4 ,该字段的值必须是 4 。
头部长度
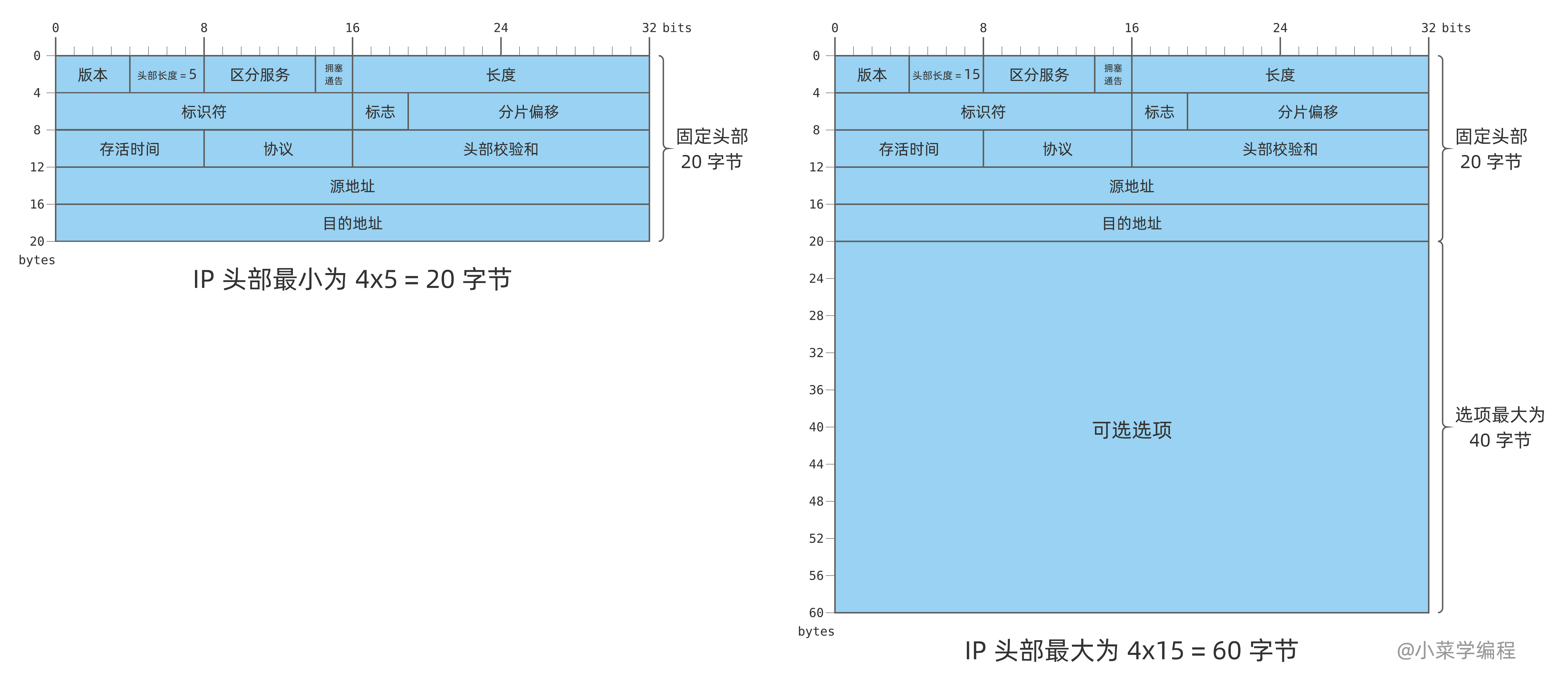
由于 IP 头部可能包含数量不一的 可选选项 ,因此需要一个字段来记录头部大小,进而确定数据的偏移量,这就是 头部长度 ( internet header length , IHL )。
IHL 字段同样占用 4 个比特,它用来说明头部由多少个 32 位字组成。上述 IP 包结构图中,每一行就是一个 32 位字,由 32 个比特位构成,也就是 4 字节。因此,头部字节数可以这样计算:
$$IP包头部字节数 = 4 \times IHL$$
如果 IP 包不包含任何选项,头部大小为 5 个 32 位字(图中前 5 行),IHL 字段值则为 5 ( 二进制 0101 )。IHL 最大值为 15 ( 二进制 1111 ),因此 IP 头部最大为 60 字节,其中选项部分为 40 字节。
区分服务
区分服务 ( differentiated services ,DS )占 6 比特,一般情况下不使用。只有使用区分服务时,这个字段才起作用,例如:需要实时数据流的 VoIP 。
显式拥塞通告
显式拥塞通告( explicit congestion notification ,ECN ),允许在不丢包的同时通知对方网络拥塞的发生。
全长
全长 ( total length )字段占 16 位,它定义了 IP 包的总长度,包括头部和数据,单位为字节。这个字段最大值是 $2^{16}-1=65535$,因此理论上最大的 IP 可以达到 65535 字节。当 IP 包长度大于下层数据链路协议 MTU 时,IP 包就必须被 分片 (拆分成多个包)。
标识符
标识符 ( identification )字段占 16 比特,用来唯一标识一个包的所有分片。因为 IP 包不一定都能按时到达,在重组时需要知道分片所属的 IP 包,标识符字段就是一个 IP 包的 ID 。它一般由全局自增计数器生成,每发一个包,计数器就自动加一。
关于 IP 包分片技术的更多细节,将在后续章节中展开介绍。
标志
标识 ( flags )字段占 3 比特,包含几个用于控制和识别分片的标志位:
- 第 0 位,保留,必须为 0 ;
- 第 1 位,禁止分片( don’t fragment ,DF ),该位为 0 才允许分片;
- 第 2 位,更多分片( more fragment ,MF ),该位为 1 表示后面还有分片,为 0 表示已经是最后一个分片;
分片偏移
分片偏移 ( fragment offset )字段占 13 比特,表示一个分片相对于原始 IP 包开头的偏移量,以 8 字节为单位。
存活时间
存活时间 ( time to live ,TTL )字段占 8 比特,避免 IP 包因陷入路由环路而永远存在。存活时间以秒为单位,但在具体实现中成了一个跳数计数器:IP 包每经过一个路由器,TTL 都被减一,直到 TTL 为零时则被丢弃。
协议
协议 ( protocol )字段占 8 比特,表示 IP 包数据类型。通常情况下,IP 包数据承载着一个上层协议报文,常见的有下面这些:
| 协议字段值 | 协议名 | 缩写 |
|---|---|---|
| 1 | 互联网控制消息协议 | ICMP |
| 2 | 互联网组管理协议 | IGMP |
| 6 | 传输控制协议 | TCP |
| 17 | 用户数据报协议 | UDP |
| 89 | 开发式最短路径优先 | OSPF |
| 132 | 流控制传输协议 | SCTP |
这也是一个非常典型的 复用/分用 字段:不同的上层协议报文,都可以利用 IP 协议提供的能力,互联网主机间进行传输。
头部校验和
头部校验和 ( header checksum )字段占 16 比特,与以太网帧校验和字段类似,用于对报文进行查错。
注意到,该字段只对 IP 头部查错,而不关心数据部分。这是因为 IP 包数据一般用来承载上层协议报文,例如 UDP 和 TCP ,而它们的报文都有自己的校验和字段。
每一跳路由收到 IP 包后,都要重新计算头部校验和并与该字段对比,不一致则将其丢弃。路由转发 IP 包前,也要重新计算并填写该字段,因为头部中的一些字段可能发生变化——每次转发,TTL 字段都要减一。
源地址
源地址 ( source address ),占用 32 比特,也就是 4 字节,表示 IP 包发送方的地址。
IP 地址由 32 位组成,理论上可以表示多达 $2^{32} = 4294967296$ (约等于 40 亿)台主机。实际上,IP 地址按用途分成几类,能用于公网通信的 IP 地址没有这么多。
- 公网地址
- 内网地址
- 本地地址
- 多播地址
- 广播地址
关于 IP 地址结构和类别,后续有独立章节专门展开介绍。
目的地址
目的地址 ( destination address ),格式与源地址相同,表示 IP 包接收方的地址。
选项
这是 IP 包的可选字段,并不常用,后续用到时再结合具体场景来讲解。
【小菜学网络】系列文章首发于公众号【小菜学编程】,敬请关注:

