 小菜学编程
小菜学编程

传输层引入了 端口 ( port )的概念,很好地实现了进程间通信能力。我们已经学过这一层中的 UDP 协议,它是一种 面向数据报 的传输层协议。
UDP 协议的局限性
UDP 协议非常简单,它只是在 IP 协议的基础之上,加入 端口号 来区分收发进程,因此也有不少局限性。
网络丢包
我们知道,UDP 数据报需要借助 IP 包提供的点对点传输能力,从一台主机发往另一台主机。
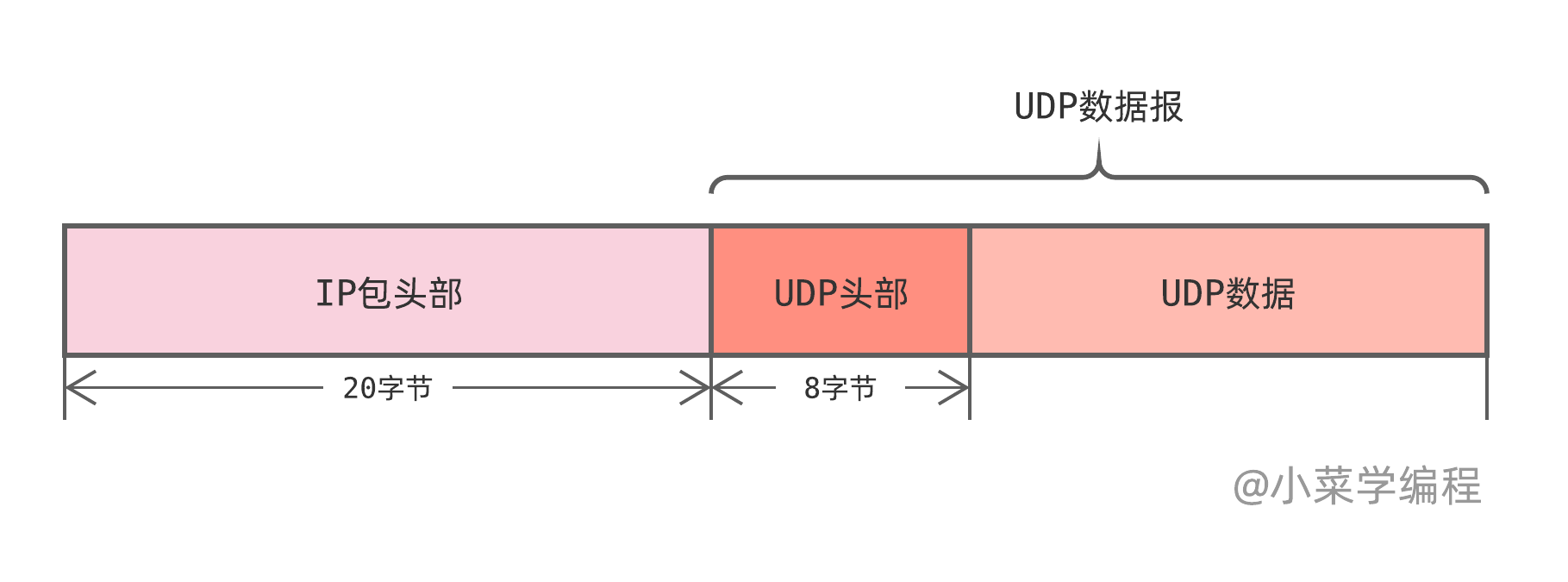
而 IP 协议只是一种“尽力而为”的网络协议,并非完全可靠,它无法保证 IP 包一定能够送达目标主机。实际上,由于网络链路拥堵或者中间路由设备故障的存在,IP 丢包现象时有发生。
当应用程序通过 UDP 协议发送数据,UDP 数据包最终需要搭载在 IP 包中发往目标主机。如果在这个过程中,承载 UDP 数据包的 IP 包丢掉了,UDP 数据包也就无法送达目标进程。
因此,UDP 协议是 不可靠 的,数据随时可能会丢。使用 UDP 协议通信的应用程序,需要自行解决丢包问题,比如实现超时重传机制。
数据乱序
由于每个 IP 包在网络中独立路由,不同的 IP 包可能会走不同的网络路径,它们到达目标主机的次序便无法预测。而 UDP 数据包直接搭载在 IP 包中进行传输,因此 UDP 协议无法保证数据按发送顺序准确送达。
举个例子,主机①向主机②连续发送 3 个数据报,数据报封装在 IP 包中在网络传输。这三个 IP 包有可能会走完全不同的路径,去往主机②。路径选择由路由器决定,主机和应用程序基本无法对此施加影响。
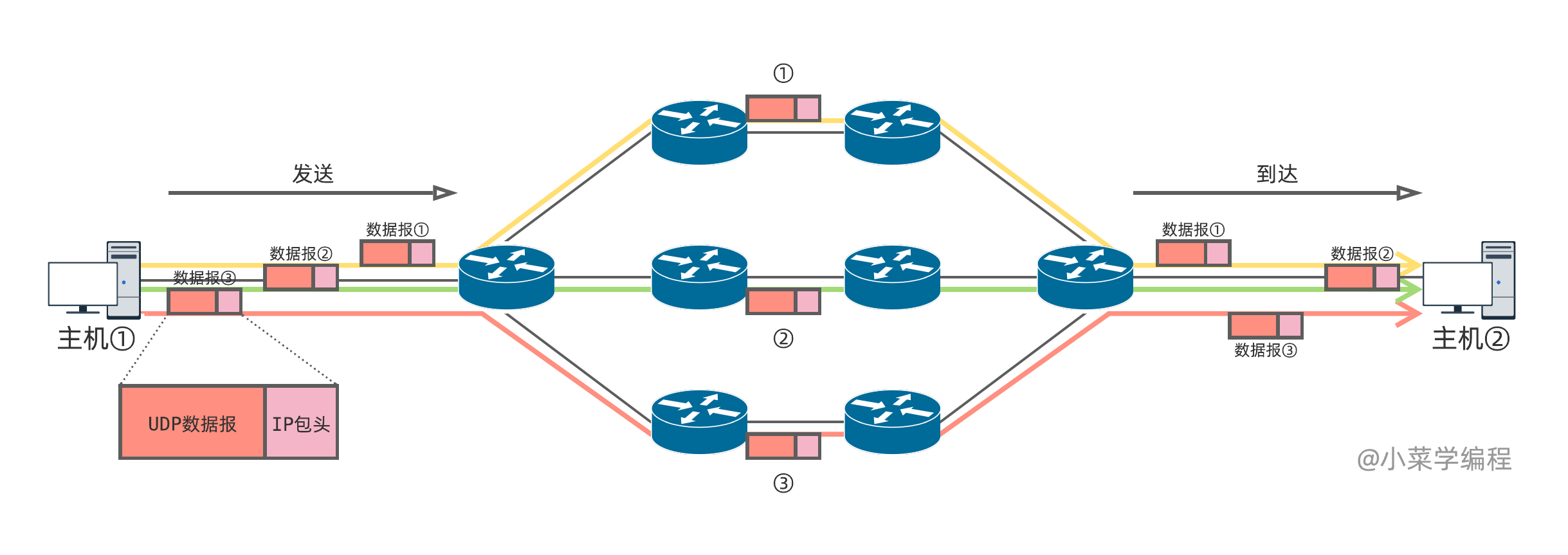
这样一来,先发送的 UDP 数据,未必能先到达。上图例子中,UDP 数据包②和③,比①更早达到,也就是说数据顺序乱掉了。
由此可见,UDP 协议无法保证数据顺序。对数据顺序有严格要求的应用程序,只能自行解决乱序问题,做法如下:
- 发送方为数据加上序号;
- 接收方按序号将数据排序;
此外,UDP 协议没有流量控制机制,就算接收方处理速度跟不上,发送方可能还会傻傻地发送数据。它也没有拥塞控制机制,发送方无法感知网络拥塞情况,因而也无法据此调节发送速度。
可靠流式协议 TCP
为解决 UDP 协议的局限性,应用程序需要做很多工作。为此,网络先驱们设计了一种更高级的传输层协议—— TCP 协议。
TCP 是 传输控制协议( Transmission Control Protocol )的简称,它是一种 面向连接的流式协议 ,可为应用程序提供 可靠的字节流传输服务 。
那么,TCP 协议到底是如何做到这些的呢?
连接建立
为保证可靠性,TCP 需要先建立连接才能开始传输数据。TCP 连接建立的过程大致是这样的:

- 连接主动发起方(一般是客户端),向被动连接方(一般是服务端)发出
SYN; - 被动连接方收到
SYN后,向主动发起方回复SYN+ACK; - 主动发起方收到
SYN后,向被动连接方回复ACK;
其中,SYN 指令表示序号同步请求,ACK 表示确认,即对同步请求进行确认。
经过这三步后,TCP 连接成功建立,双方可以开始发送数据。这个过程也被形象地称为”三次握手“。
接收确认
TCP 将数据组织成连续的字节流,每个字节均可由一个唯一的序号来标识:
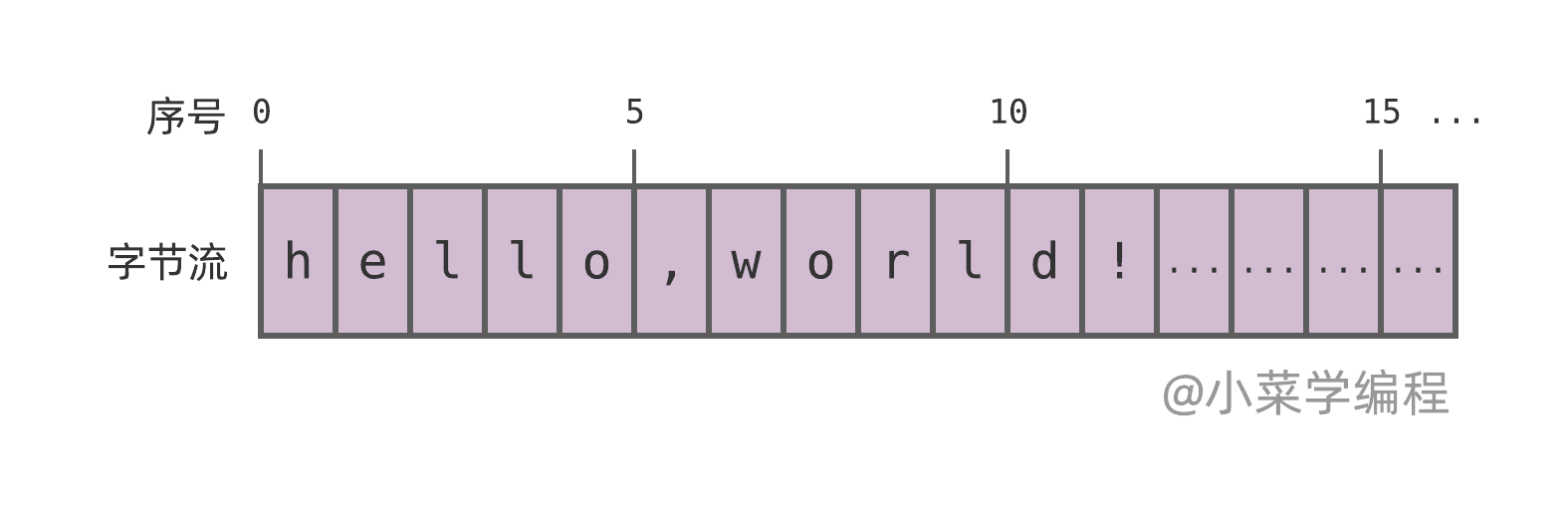
为了简化讨论,上图假设序号从 0 开始:字节流第一个字节为 0 ;第二个字节为 1 ;以此类推。
实际上,出于安全性和健壮性考虑,TCP 序号并非从 0 开始,而是有目的地“随机”选择。在三次握手阶段,SYN 包会将本端挑选的起始序号告诉对端。

TCP 在发送数据时,会将数据的 起始序号 和 长度 告诉对端。接收方收到数据后,将发送 ACK 对数据进行确认。ACK 中包含确认序号,它的值为最后一个已接收字节的序号加一,也就是接收方期望收到的新数据的起始序号。
如下图,假设主机①向主机②发送一段数据。它告诉主机②,数据的起始字节序号为 1000 ,总共 100 字节,最后一个字节的序号为 1099 :
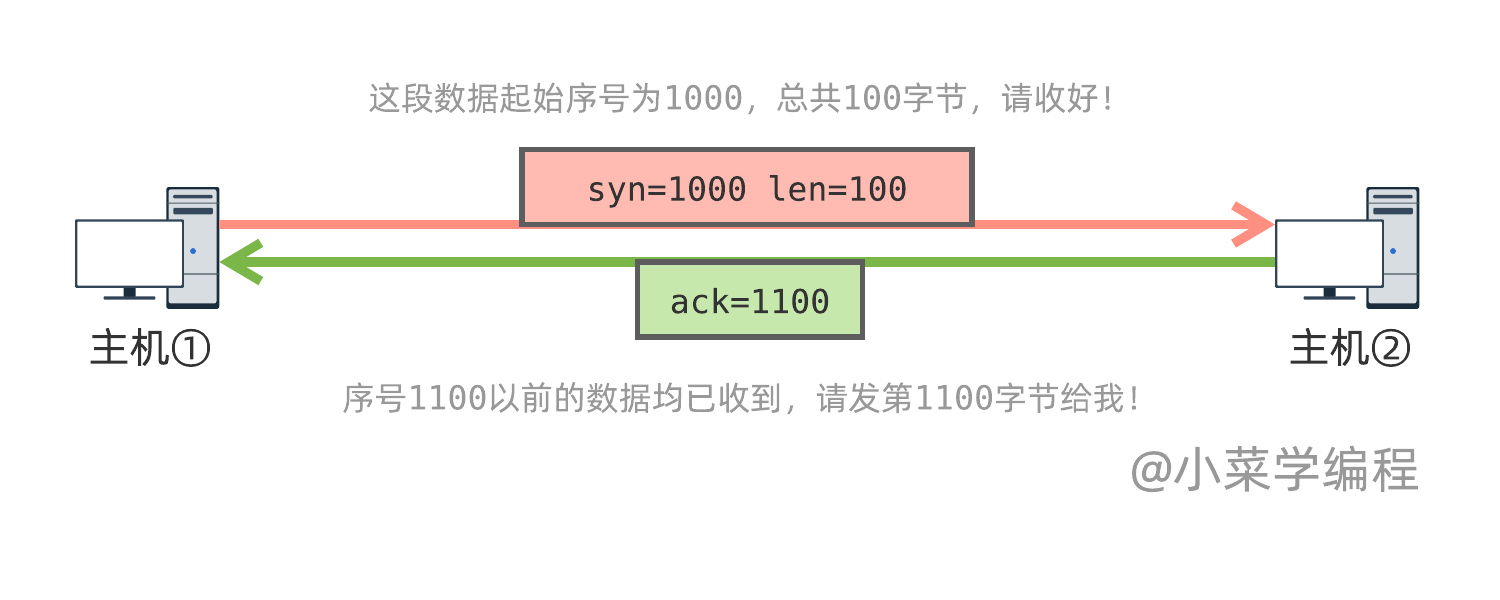
主机②收到数据后,发送 ACK 对数据进行确认,确认序号为 1100 。这相当于告诉主机①:序号 1100 以前的数据均已收到,可以发序号 1100 的数据给我了。
这样一来,只要主机①收到 ACK ,它就可以确定:数据已经成功送达了。
超时重传
如果发送方迟迟没有收到接收方的确认,说明数据很有可能在传输的过程中丢掉了。这时,发送方只能 重传 数据。
实际上,发送方在发送数据的同时,将启动一个定时器。如果在规定的时间内没有收到 ACK ,它就开始重传数据。具体细节先按下不表,等后续章节再展开。
流量控制
不同主机处理能力各有差异,发送方和接收方处理速度协调不好就会有大问题。举个例子,如果接收方处理速度较慢,发送方还拼命地发送数据,就只能白白浪费网络资源了。
好在 TCP 实现了流量控制机制,使得发送方可以根据接收方的处理速度,自动调节发送速度。那么,TCP 是如何做到这点的呢?
根据 TCP 协议规定,接收方需要维护一个 接收窗口 ,我们可以将它看作内存中的一个缓冲区。在连接建立和数据传输的过程中,接收方会将自己的接收窗口大小通告给发送方。发送方必须保证,发送的数据不超过接收窗口。如果接收窗口被占满,发送方就暂停发送新数据。
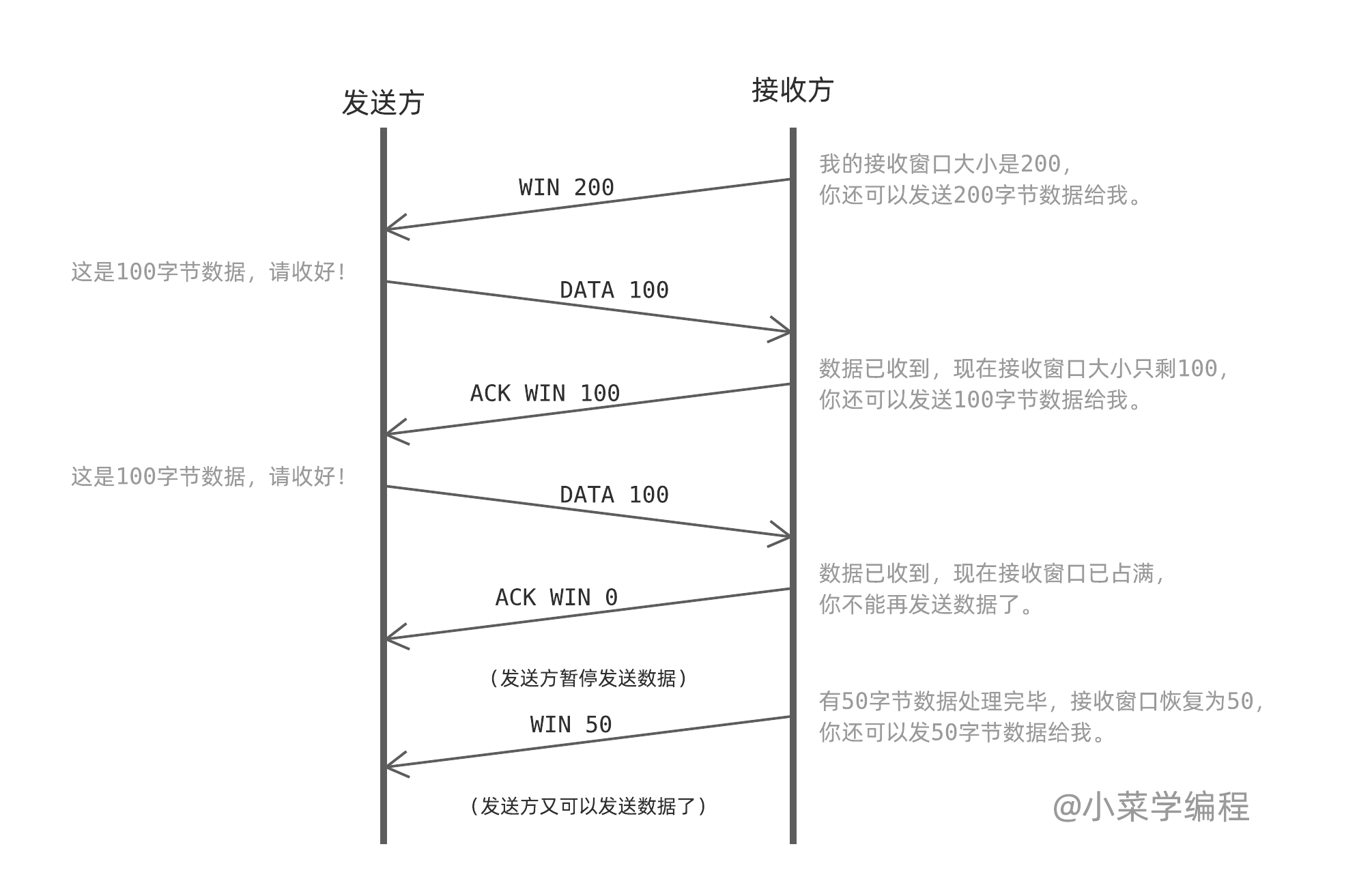
拥塞控制
如果网络链路发生拥塞,丢包概率就会急剧上升。如果这时发送方还大量发送数据,除了让链路更加拥塞外,没有任何意义。
好在 TCP 实现了拥塞控制机制,可以根据网络拥塞状况,自动调节发送速度。那么,TCP 又是如何做到这一点的呢?
TCP 发送方自己在内部维护了一个 发送窗口 ,也叫做 拥塞窗口 。这是一个为发送策略算法服务的虚拟概念,表示可以发送的字节数(包含已经发送但仍未确认部分)。
TCP 连接刚建立时,发送窗口一般都比较小,比如只有 10 字节。这就保证了,TCP 一开始的发送速度比较有限,因为它还不知道网络链路的运行状况。
如果发送方收到一个 ACK ,说明数据成功送达对端。这也意味着网络状况相对良好,可以将发送窗口调大。
发送窗口一开始呈指数增长,比如每收到一个 ACK 就将它翻倍。假设发送窗口一开始被初始化为 10 ,那它将沿着 10 、 20 、40 、80 、160 这样的路径增长。
当接收窗口增大到一定水平,增长速度降为线性增长。例如,当发送窗口增长到 160 后,每次只增加 10 ,直到达到既定上限。
这就是 TCP 的 慢启动 过程,在网络状况良好的前提下,不断提高发送速度。
如果网络发生拥塞,有数据丢包,这时 TCP 必须重传数据。发送方在重传数据的同时,还会降低发送窗口大小。
这种情况下,大部分 TCP 实现会将发送窗口降为原来的一半,以便快速响应,避免进一步堵塞网络。这个机制也被称为 指数退避 。
这就是 TCP 拥塞控制的基本思想,我们先有个大概印象即可,具体细节等后续再展开介绍。
连接关闭
TCP 连接建立后,我们得到了两个独立的字节传输流。他们传输方向相反,一起构成了全双工的传输信道。

当某个方向的数据传输完毕,发送方可以发送 FIN 指令,告诉接收方该方向传输流已经关闭。先关闭传输流的一方称为主动关闭方,另一方则成为被动关闭方。
假设主机①数据发送完毕,它向主机②发出 FIN ,成为主动关闭方;主机②则成为被动关闭方,它回复 ACK 后,从主机①到主机②的数据流关闭。
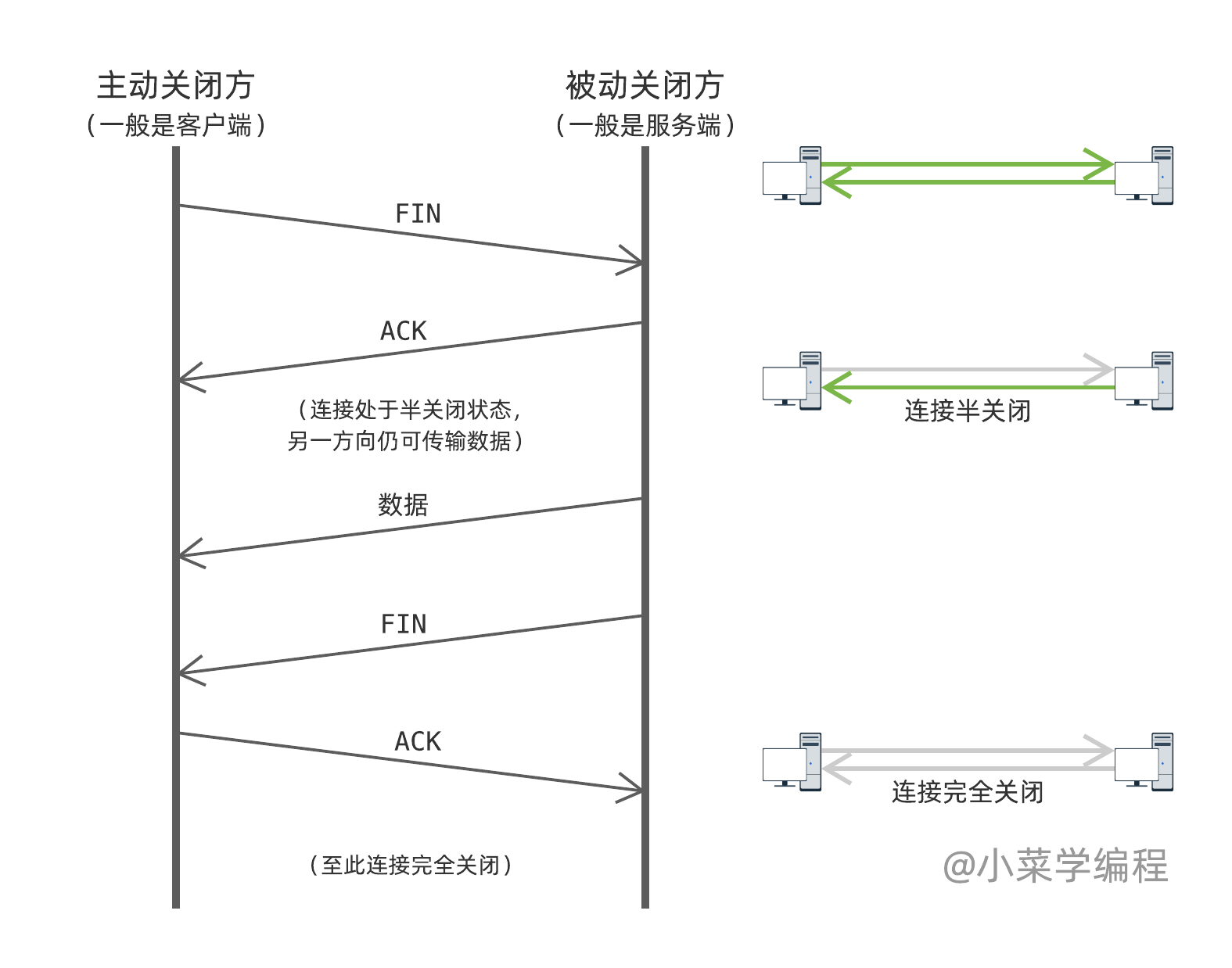
这时,连接处于 半关闭状态 ,反方向的数据流仍然有效。也就是说,这时主机②还可以向主机①发送数据。
当主机②也发完数据,它同样发出 FIN 指令,告诉主机①数据流关闭;主机①收到 FIN 并回复 ACK 后,连接就完全关闭了。这就是 TCP 连接关闭的主要步骤,也被形象地称为“四次挥手”。
来到这里,相信大家对 TCP 协议已经有了一些基本了解。TCP 协议可以说是 TCP/IP 协议栈中最重要,也是最复杂的协议。它还有很多的细节,等着我们进一步深入学习,敬请期待!
【小菜学网络】系列文章首发于公众号【小菜学编程】,敬请关注:

