 小菜学编程
小菜学编程

开发网络程序离不开套接字编程,基于 TCP 通信的程序也不例外。我们知道 TCP 应用可以分为 客户端( client )和 服务器( server )两种角色,本节先介绍如何编写 TCP 客户端程序。
连接套接字
跟 UDP 一样,想要发起 TCP 通信,必须通过操作系统提供的 套接字( socket )。
我们知道 TCP 是一个相对复杂的传输层协议,涉及的通信细节非常繁琐:
- 数据序号;
- 接收确认( ACK );
- 超时重传;
- 流量控制;
- 拥塞控制;
- 各种超时定时器;
- 接收缓冲区;
- 发送缓冲区;
如果这些都要每个应用程序单独实现,想想就头大!因此,出于程序复用性考虑,操作系统内核实现了网络协议栈,并将编程接口以套接字形式提供给应用程序。
这样上层应用程序只专注于数据收发,无须关心底层通信细节,复杂性得到极大简化。
那么,一个 TCP 连接套接字,又包含哪些要素呢?
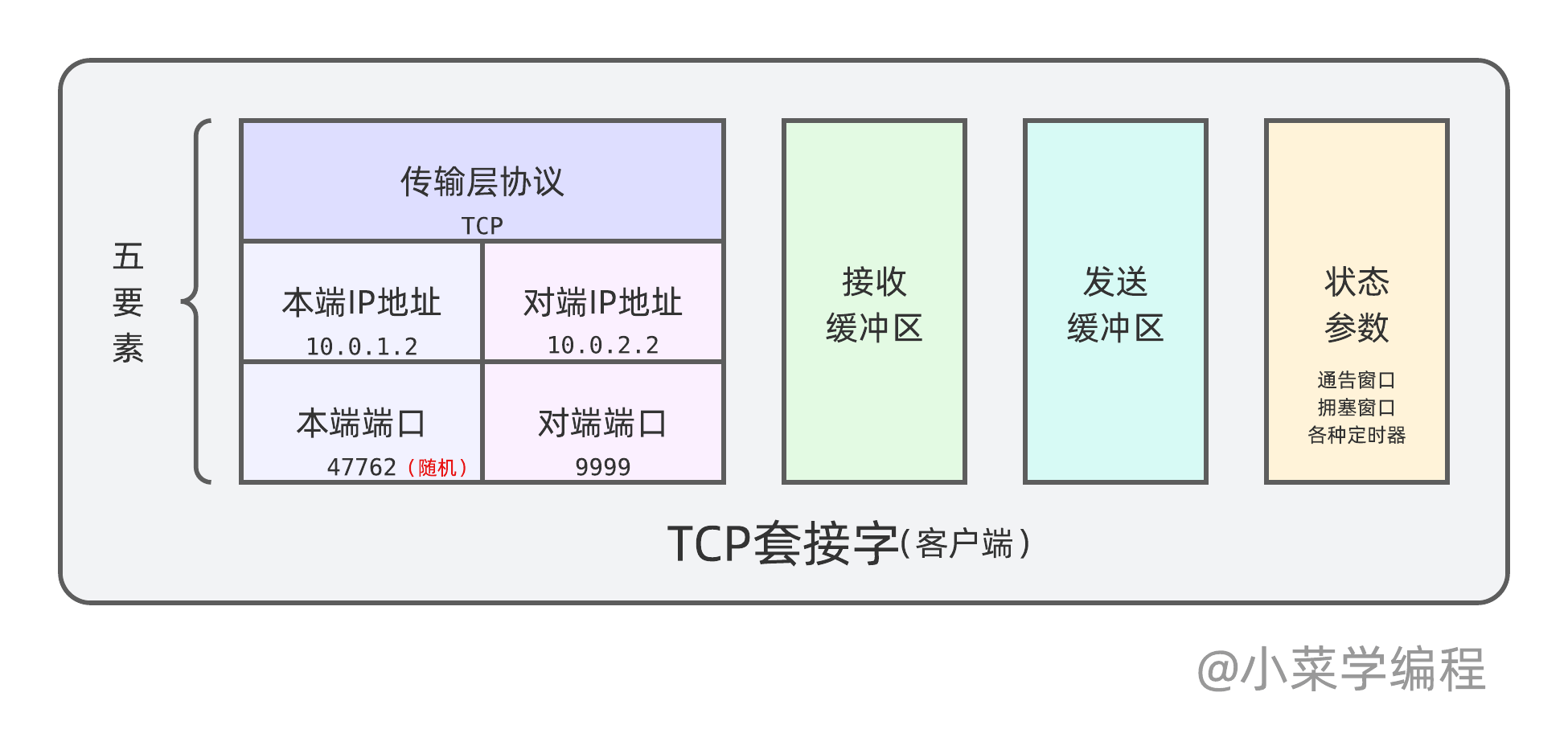
如上图,一个 TCP 套接字包含由两端 IP 地址和端口组成四元组,四元组唯一确定一个 TCP 连接。此外,操作系统内核还会为套接字分配接收缓冲区和发送缓冲区,并维护各种状态和参数。
应用程序先执行系统调用创建套接字,操作系统建好套接字后将唯一标识返回给应用程序。以 Linux 为例,套接字以文件描述符的形式返回给应用程序。后续应用程序可以执行其他系统调用,通过文件描述符操作套接字完成通信任务。
关键步骤
TCP 客户端通信程序需要执行的关键系统调用大致如下:
- socket ,创建套接字;
- connect ,操作套接字与服务器建立 TCP 连接,内核协议栈接到调用后便执行三次握手;
- send ,操作套接字向对端发送数据;
- recv ,从套接字中取出对端发来的数据;
- close ,操作套接字关闭连接,内核协议栈将执行四次挥手;
创建套接字
跟 UDP 套接字一样,创建套接字也是执行 socket 系统调用,但参数有所不同:
|
|
- domain 参数指定通信协议域,PF_INET 表示表示 IPv4 网络通信;
- type 参数指定协议类型,SOCK_STREAM 表示流式协议,即 TCP ;
- protocol 参数执行具体的网络协议(前两个参数已经可以确定协议,因此传零即可);
socket 系统调用成功建好套接字后,将返回一个文件描述符,应用程序可以通过它来操作套接字进行通信。如果执行失败,socket 系统调用将返回 -1 ,错误信息则保存在 errno 变量。
建立连接
客户端程序建好套接字后,需要先执行 connect 系统调用跟服务器建立连接后,才能开始传输数据。执行 connect 系统调用,需要传 3 个参数:
- sockfd ,代表套接字的文件描述符,由此告诉内核操作哪个套接字;
- addr ,服务器的 IP 地址和端口,通常保存在 sockaddr_in 结构体;
- addr_len ,第二个参数 addr 的长度,单位是字节数;
因此,我们需要先准备 sockaddr_in 结构体,并将服务器地址信息填充进去:
|
|
准备好地址结构体后,即可调用 connect 系统调用建立连接:
|
|
connect 系统调用将服务器地址和端口信息带到内核,由内核负责执行三次握手:
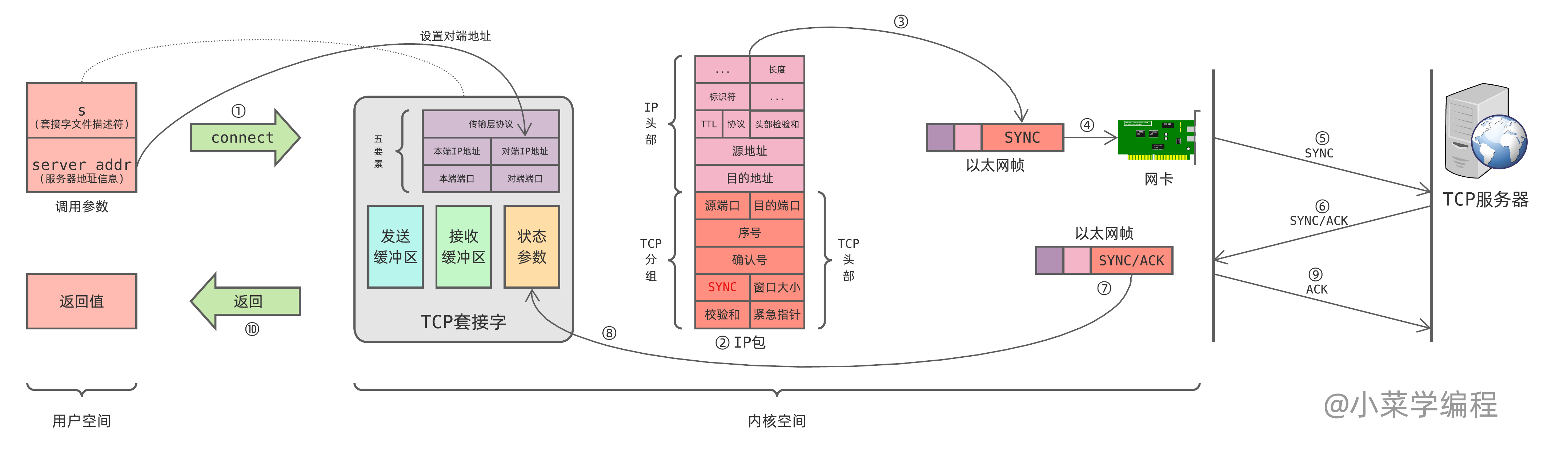
- 应用程序调用 connect 系统调用,服务器地址端口信息设置到套接字对端信息;
- 根据本机路由表和服务器 IP 地址,决定 IP 包发送网卡和下一跳地址;
- 本端地址取发送网卡的 IP 地址;
- 本端端口由内核随机分配;
- 封装 IP 包发送 SYNC 分组,源和目的 IP 地址和端口来自套接字四元组;
- 根据发送网卡和下一跳的物理地址( ARP ),将 IP 包封装成数据链路层帧准备发送;
- 将以太网帧通过网卡发送出去;
- SYNC 包在网络上传输并最终到达目标 TCP 服务器;
- TCP 服务器回复 SYNC/ACK 包;
- 网卡收到承载 SYNC/ACK 的以太网帧;
- 解析以太网帧得到 SYNC/ACK 分组,将套接字状态更新为已连接;
- 封装 ACK 分组发给 TCP 服务器,三次握手过程执行完毕;
- connect 系统调用返回,应用程序检查返回值判断是否连接成功;
阻塞模式下, connect 系统调用将一直等待,直到操作系统内核执行完三次握手成功建立连接,或连接建立超时。如果连接建立失败,connect 系统调用将返回 -1 ,错误原因同样保存在 errno 。
TCP 连接建立失败的原因有很多,包括:①服务器 IP 不可达;②服务器响应超时;③服务器端口没开等等。
发送数据
TCP 连接成功建立后,我们就可以执行 send 系统调用向服务器发送数据了:
|
|
send 系统调用跟我们在 UDP 编程中用过的 sendto 类似,但参数更少:
- sockfd ,套接字的文件描述符;
- buf ,待发送数据的地址;
- len ,数据长度;
- flags ,一些标志位,这里传 0 即可,先不展开介绍;
跟 sendto 相比,send 系统调用不用传接收方地址。由于 TCP 是面向连接的传输层协议,套接字建立好连接后,接收方地址是确定的,因此不用再传。
与 TCP 不同,UDP 是面向数据报的协议,没有连接的概念。一个 UDP 套接字可以同时跟多个不同的对端进行通信,因此必须指定接收方地址。UDP 套接字也可以执行 connect 系统调用固化对端地址(但不会建立连接),这时也不用传接收方地址,指定 send 系统调用就行。
send 系统调用将要发送的数据拷贝到套接字的发送缓冲区,然后就返回了:
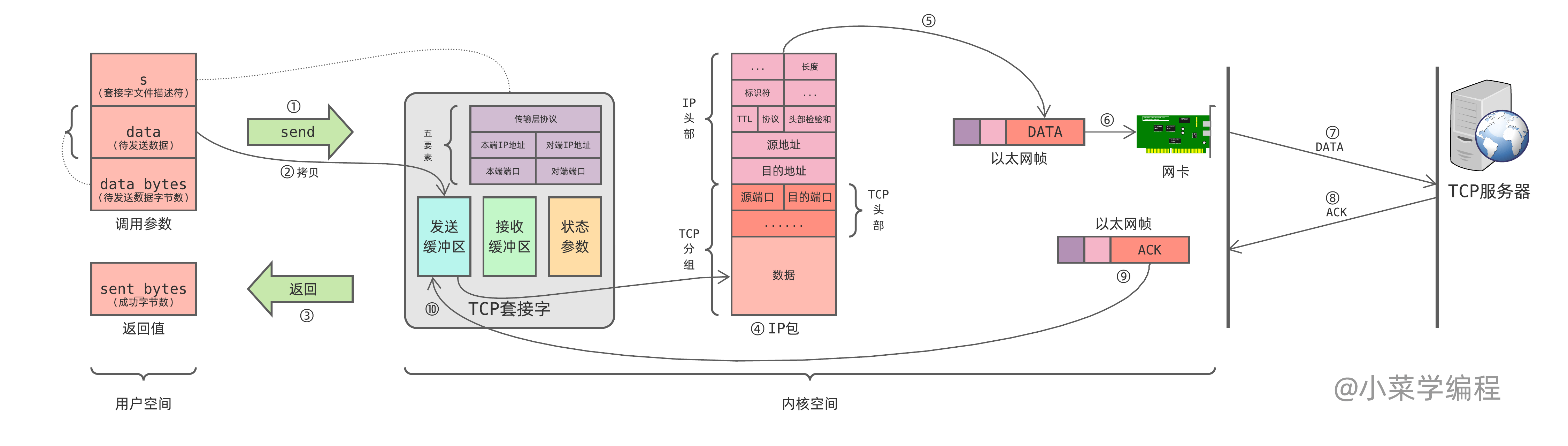
- 应用程序调用 send 系统调用发送数据,传数据首地址 data 和 数据字节数 data_bytes ;
- 内核将程序要发送的数据,从用户空间拷贝到套接字的发送缓冲区;
- send 系统调用执行完毕,返回成功写入发送缓冲区的字节数;
- 发送缓冲区大小可能小于数据大小,因此可能部分成功;
- 数据进入发送缓冲区不意味着数据顺利送达对端;
- 如果发送缓冲区已满,阻塞模式下 send 会等待缓冲区释放(已发数据顺利送达);
- 内核协议栈封装 TCP 分组报文发送数据,源目地址由套接字四元组决定;
- 承载 TCP 数据分组的 IP 包,由本地路由表决定出口设备,并封装成数据链路层帧准备发送;
- 数据链路层帧从网卡设备发送出去;
- TCP 数据分组由 IP 包承载在网络中传输,最终达到 TCP 服务器;
- TCP 服务器收到数据分组,回复 ACK 确认;
- ACK 确认以数据链路层帧的形式被网卡接收;
- 协议栈解析收到的 ACK 确认分组,据此将成功送达的数据从缓冲区中移除;
需要特别注意,就算 send 系统调用执行成功,也不能保证数据成功送达对端,因为它将数据拷贝到套接字的发送缓冲区后就返回了。此外,由于发送缓冲区可能比数据小,send 会部分成功。
接收数据
跟接收 UDP 数据一样,接收 TCP 数据前需要先准备缓冲区空间,再执行 recv 系统调用:
|
|
recv 系统调用同样不关心对端地址(连接后就确定且不再改变),它只需要传这几个参数:
- sockfd ,套接字的文件描述符;
- buf ,用于保存数据的缓冲区地址;
- len ,数据缓冲区长度;
- flags ,一些标志位,这里传 0 即可,先不展开介绍;
recv 系统调用其实只是负责将套接字接收缓冲区中收到的数据,拷贝到用户空间:
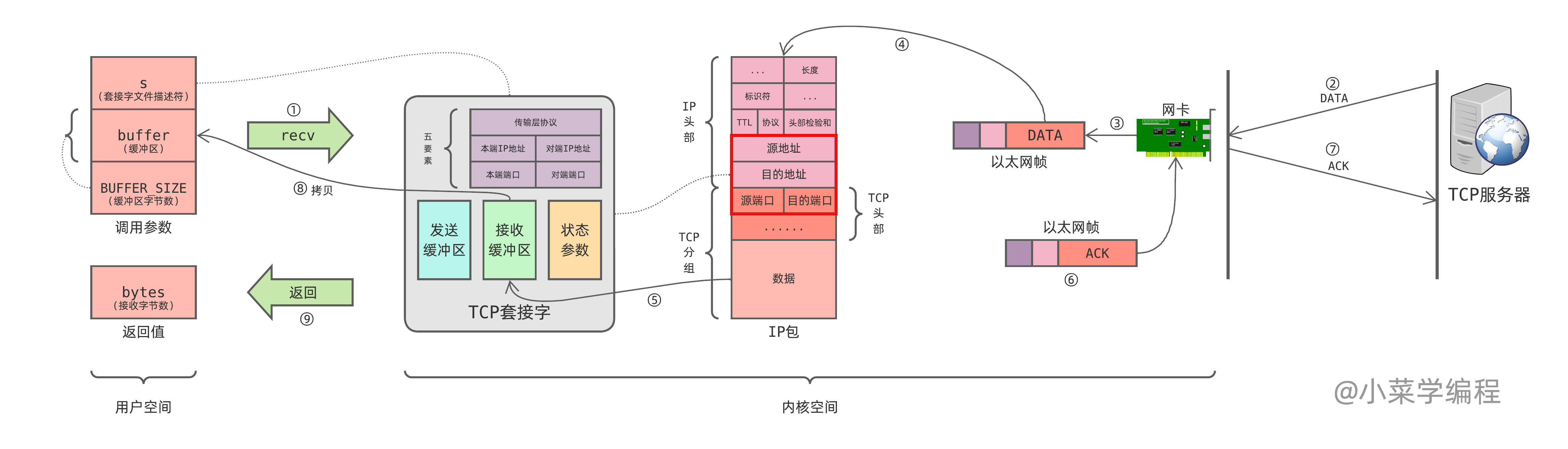
- 应用程序执行 recv 系统调用接收数据;
- 如果接收缓冲区中还有未读数据,直接拷贝并返回;
- 如果接收缓冲区中还没有数据,阻塞模式下会等待对端发送数据;
- 对端通过 TCP 数据分组发来数据;
- TCP 数据分组以数据链路层帧的形式,被网卡设备收到;
- 内核协议栈解析数据链路层帧,得到 TCP 分组(分组封装在 IP 包中);
- 内核协议栈根据分组中的源目地址找到对应的套接字,并将数据拷贝到接收缓冲区;
- 内核协议栈封装 ACK 分组,向对端进行确认;
- ACK 分组通过网络送达对端;
- recv 系统调用将数据从接收缓冲区,拷贝到用户空间;
- 释放占用的接收缓冲区空间,通告对端可以发更多数据(流量控制、通告窗口);
- recv 系统调用执行完毕,返回成功接收的字节数;
recv 系统调用跟内核中的收包逻辑并无严格的先后顺序,两者利用接收缓冲区对齐步调:
- 内核协议栈收到对端发来的数据,先保存在接收缓冲区;
- 如果接收缓冲区有未读数据,recv 系统调用直接读取数据并返回;
- 如果接收缓冲区没有数据,阻塞模式下 recv 可以等待直到对端发来数据;
- 如果接收缓冲区已满,对端就暂停发送数据(流量控制机制);
- recv 系统调用将数据从接收缓冲区取走就释放占用空间,并通过窗口通告对端;
关闭套接字
应用程序通信完毕后,可以执行 close 系统调用关闭套接字:
|
|
操作系统内核协议栈接到该系统调用后,将回收文件描述符,执行四次挥手并销毁套接字。
完整程序
我们在实验中使用 tcp-upper-client 客户端程序跟服务器通信,它的完整源码如下:
|
|
大家可以利用本节学到的知识,自己开发 tcp-upper-client 程序练练手。包含命令行参数处理函数在内的完整代码可从 Github 上获取,地址为:tcp-upper 。源代码结构大致如下:
- argparse.c ,命令行参数处理函数源文件;
- argparse.h 。命令行参数处理函数头文件;
- client.c ,TCP 客户端程序源文件;
- Makefile ,用于编译构建;
程序编译
在 Linux 系统上,进入 tcp-upper 源码目录,执行 make 命令即可完成编译:
|
|
程序编译成功后,可以在当前目录下看到生成的可执行程序 client ,可以直接运行:
|
|
如果不想使用 make 命令,也可以直接执行 gcc 命令进行编译:
|
|
这个命令的意思是编译 client.c 和 argparse.c ,生成的可执行程序命名为 client 。
【小菜学网络】系列文章首发于公众号【小菜学编程】,敬请关注:

