 小菜学编程
小菜学编程

摘要
Raft 是一种用于管理 日志复制 ( replicated log )的 共识算法 ( consensus algorithm )。 它提供了一种 等价 于 Paxos 的做法,并且同样高效,只是结构有所不同; Raft 结构比 Paxos 更好理解 ,因而更容易在实际系统中落地。 为追求 易理解性 ( understandability ), Raft 将达成共识的关键要素分成: 领袖选举 ( leader election )、 日志复制 ( log replication )以及 安全性 ( safety ), 并执行更高级别的一致性以减少必须考虑的状态数。 从用户学习效果来看, Raft 比 Paxos 更容易被学生掌握。 此外, Raft 引入了一种新机制来支持 集群成员变更 , 以 重叠过半数 ( overlapping majorities )保证安全性。
1 简介
共识算法让多台机器组成一个统一连贯的 整体 ,而不受某些成员故障的影响。 因此,这类算法在构建 高可用海量软件系统 中扮演着关键角色。 过去几十年,Paxos 算法一直是这个领域的主宰: 大部分共识算法实现要么基于 Paxos 要么从 Paxos 衍生而来; Paxos 也成为在共识算法教学的主要工具。
然而, Paxos 太难理解了 ! 为了 Paxos 不那么高冷,各路牛人进行了大量的改良尝试,但收效甚微。 此外,为了支持生产系统, Paxos 结构还需要不少复杂改动。 因此,不管是系统研发人员还是学生,均对 Paxos 谈虎色变。
我们也曾深陷 Paxos 泥潭,因而立志寻找一种新共识算法,改善系统构建以及教学。 我们的出发点比较取巧,主要目标聚焦于 易理解性 : 我们能否设计出一种结构比 Paxos 更好理解,并且足以胜任生产要求的共识算法? 此外,我们希望算法能够刺激开发灵感,这对系统研发人员意义非凡。 算法有效工作非常重要,直白的工作原理同样重要。
经过努力,我们提出了一种新的共识算法—— Raft 算法。 为了提高 易理解性 ,我们在设计 Raft 时用到不少技巧,包括: 问题分解 (分解成领袖选举、日志复制以及安全性三个子问题), 以及 状态规模缩减 (与 Paxos 相比, Raft 降低了不确定性以及服务器间不一致的可能性)。 对两所大学 43 名学生的学习效果进行调研,结果表明 Raft 比 Paxos 更容易掌握: 学完两种算法后,其中 33 名学生 Raft 答题情况更好。
Raft 与现有共识算法有不少相似之处(特别是 Oki 和 Liskov 的 Viewstamped Replication ), 但以下特性却与众不同:
- 强领袖 :与其他共识算法相比, Raft 采用一种更强势的领袖模式。 例如,日志条目只从领袖流向其他服务器。 这样做简化了日志复制管理,也更好理解。
- 领袖选举 : Raft 采用 随机计时器 实现领袖选举。 这种做法只须在服务器心跳的基础上加入一些处理机制,即可简单且迅速地解决选举冲突。
- 成员变更 ( membership changes ): Raft 采用 联合共识 ( joint consensus )实现集群成员变更, 过渡期间要求两份不同配置机器均过半数(重叠)。 这个特性使得集群可以在配置调整时不中断服务。
我们认为, Raft 比 Paxos 以及其他共识算法更为出色,无论是处于教育目的还是工程实现。 它更为简单,比其他算法更好理解; 它描述足够完整,足以用于构建实际系统; 它已有若干开源实现,并被不少公司采用; 它的安全性也得到正式证明; 它的效率也完全不亚于其他算法。
论文后续内容包括: 第 2 小节介绍 复制状态机 ( replicated state machines ); 第 3 小节讨论 Paxos 算法的优势及劣势; 第 4 小节介绍基于易理解性的设计方法; 第 5-7 小节介绍 Raft 共识算法; 第 8 小节评价 Raft 算法; 第 9 小节介绍一些相关工作。 由于篇幅关系,我们省略了一些 Raft 要素,只在扩展版中介绍。 扩展版额外讨论了客户端如何与系统交互,以及 Raft 日志空间如何回收利用等问题。
2 复制状态机
共识算法通常在 复制状态机 ( replicated state machines )上下文产生。 这种方法要求在服务器集群上运行一样的状态机副本,就算一些服务器故障也不受影响。 复制状态机用于解决 分布式系统 ( distributed systems )中的 容错 ( fault tolerance )问题。 举个例子,依赖单一领袖的海量系统,如 GFS 、 HDFS 以及 RAMCloud , 通常用一个独立的复制状态机来管理诸如 领袖选举 以及 配置存储 (领袖故障不能丢失)之类的操作。 复制状态机实例包括: Chubby 以及 ZooKeeper 。
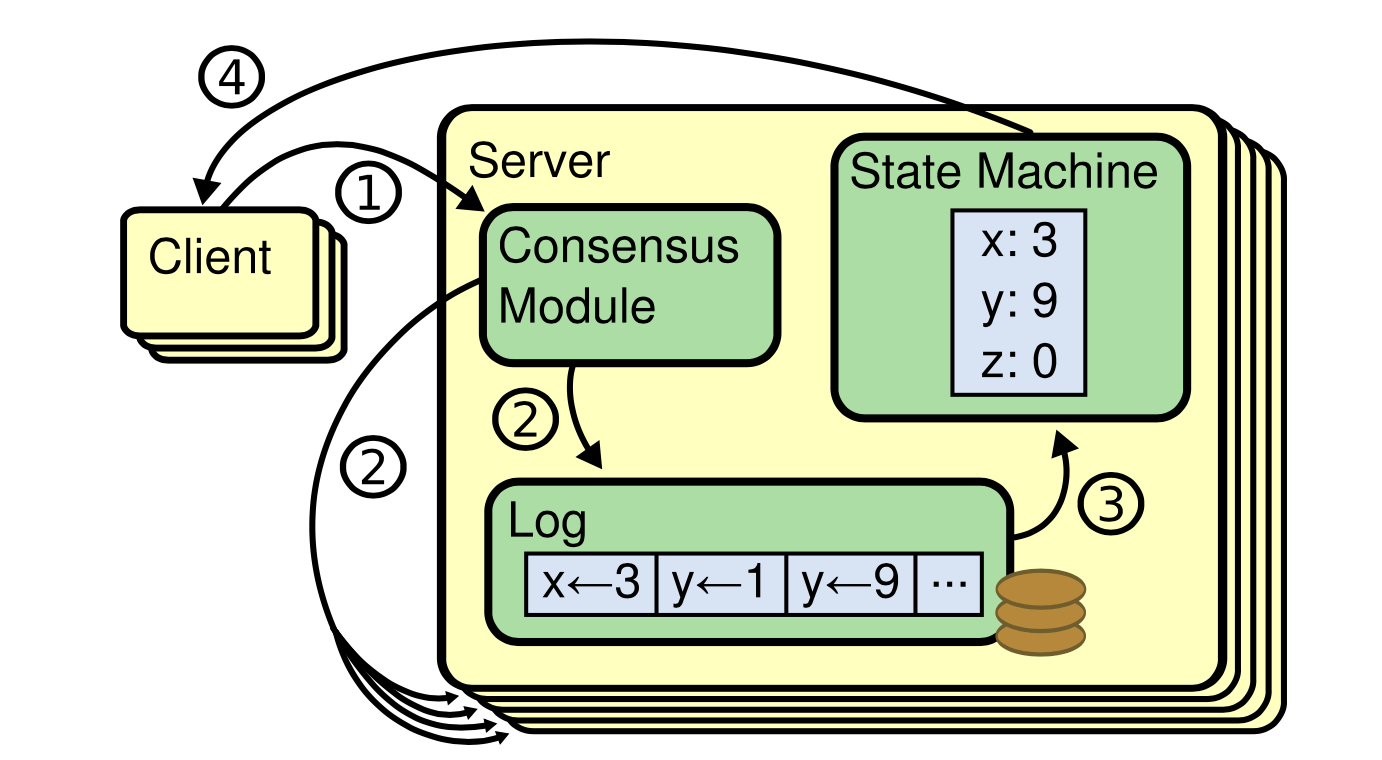
图-1 复制状态机结构 共识算法以 日志 管理客户端提交的 状态机命令 ,并复制到多台机器。 每个状态机从日志中处理 相同的命令序列 ,因此产生 相同的结果 。
复制状态机一般通过 日志复制 ( replicated log )来实现,如 图-1 所示。 每台服务器用一个日志保存命令序列,并由状态机依次执行。 每个日志包含相同的命令,顺序也一样,因此每个状态机处理的命令序列都是一样的。 由于状态机是 可确定的 ( deterministic ),计算将得到相同的状态并输出相同的结果。
确保日志副本一致性是共识算法的主要工作。 一致性模块接收来自客户端的命令并写到本地日志。 它同时与其他服务器通讯,以保证每个日志最终以 相同的顺序 包含 相同的请求 ,即便有服务器故障也是如此。 一旦命令正确复制,每台服务器将按顺序进行处理,并将结果返回给客户端。 这样一来,服务器集群便形成单一的 高可用状态机 。
一个可用于生产系统的共识算法需要具备以下特性:
- 在所有非 Byzantine 条件下保证 安全性 (不返回错误结果),包括: 网络延迟( network delays )、分区( partitions )、丢包( packet loss )等等。
- 只要 过半数 ( majority of )服务器正常,就可以保证系统的 可用性 ( availability )。 因此,一个由 5 台服务器组成的集群,能够容忍任意两台服务器故障。 服务器关机也认为是故障;服务器恢复后可以从持久性存储中恢复状态并重新加入集群。
- 不依赖时序 ( timing )保证日志一致性:时钟故障、消息延迟最多只影响 可用性 。
- 一般情况下,只要过半数机器响应相关远程调用,命令便算完成; 少部分机器响应缓慢不能影响系统性能。
3 Paxos的问题
几十年来, Leslie Lamport 的 Paxos 协议几乎就等同于 共识算法 : 在课堂上,它是传授最广的案例;大部分算法实现都以 Paxos 起步。 Paxos 先定义一个能够对单一决议(例如单个复制日志项)达成一致的协议。 我们将这个子集称为 单决议 ( single-decree ) Paxos 。 Paxos 然后将多个单决议协议组合起来,形成一系列决议,例如日志( 多Paxos multi-Paxos )。 Paxos 同样保证安全性和可用性,支持集群成员变更。 Paxos 正确性也得到证明,在正常情况下也足够高效。
不幸的是, Paxos 有两个致命缺陷。 第一个是, Paxos 非常难以理解。 论文完整描述是公认的难懂,就算付出巨大努力,也只有极少部分人真正掌握。 因此,有不少人尝试用更简单的术语描述 Paxos 。 这些阐释只聚焦于单决议 Paxos ,挑战还是不小。 我们发现,没有人能轻松玩转 Paxos ,即便是经验丰富的研究人员也是如此。 我们自己也深陷 Paxos 泥潭; 一开始我们完全没有办法理解 Paxos 协议,直到参考一些简化描述并设计自己的变体协议,这个过程花了接近一年时间!
4 易理解性设计
我们在设计 Raft 时设定了几个目标: ①算法必须有效降低研发人员的设计工作,提供完整可行的系统构建基础; ②任何条件下都保证安全性; ③典型操作条件下保证可用性; ④常见操作足够高效。 但是,我们最大的目标是 易理解性 ( understandability ),这也是最大的挑战。 普通成年人必须能够比较自然地理解该算法。 此外,算法必须提供开发灵感,以便系统研发人员进行扩展,这在实际实现中不可避免。
设计过程中,有不少技术点需要在不同的方案中选择。 这时,我们会以易理解性对待选方案进行评估: 描述这个方案是否存在困难(状态空间复杂吗?是否存在潜在问题); 读者能否轻松理解整个方案以及潜在问题?
我们意识到这种分析方法带有强烈的主观性;然而,还是采用其中两个应用广泛的技巧。 第一个做法就是众所周知的 问题分解 : 只要有可能,我们便把问题划分成可以独立解决、描述以及理解的子问题。 Raft 就将共识问题划分成: 领袖选举 、 日志复制 以及 成员变更 等子问题。
第二个做法是降低需要考虑的状态数,使系统条理更清晰,消除不确定性。 Raft 不予许日志空洞,服务器间日志不一致的情况也较少。 尽管大部分情况下我们尽量消除不确定性,有些场景不确定性却更好理解。 随机方法是一个典型例子,他引入了不确定性,却降低了状态空间——对于所有可能的选择,处理方式都是类似的(随意选择,无关紧要)。 因此,我们在 Raft 中采用随机方法以简化领袖选举算法。
5 Raft共识算法
Raft 是一个管理日志复制的算法,形式第 2 小节已介绍过。 第 5.0 小节对 Raft 算法进行浓缩 总结 ,以供快速查阅; 同时列举了算法的 关键性质 。
Raft 实现 共识算法 的思路是:选举一个 领袖 节点,由该节点全权负责管理复制日志。 领袖服务器从客户端接收 日志条目 ( log entries ),复制到其他服务器上并在合适的时机通知它们安全应用到状态机。 引入领袖这一角色后,对复制日志的管理变得简单了。 因为领袖可以自行决定并保存新条目,无须与其他服务器协商; 数据流也足够简单:从领袖流向其他服务器。 领袖可能会故障或者与其他服务器失去联系,这种情况下会重新选出一个新领袖。
引入 领袖机制 后, Raft 将共识问题分解成三个相对独立的子问题(后续章节展开讨论):
- 领袖选举 ( leader election ):领袖故障时必须选出一个新领袖( 5.2 小节);
- 日志复制 ( log relication ):领袖接收来自客户端的日志条目,并复制到整个集群, 强制其他节点接受( 5.3 小节 );
- 安全性 ( safety ):对 Raft 而言,最重要的是 状态机安全性 ( 5.0.5 小节): 只要有服务器将日志条目应用到其状态机,其他服务器就不能在相同索引下应用其他命令。 第 5.4 小节介绍 Raft 如何保证这一点; 解决方案只需在 领袖选举 (第 5.2 小节)之上新增一些额外的约束。
共识算法介绍完后,本节将进一步讨论 可用性 ( availability )问题、以及 时序 在系统中扮演的角色。
5.0 Raft要点
本节由原论文 图-2 翻译而来,是 Raft 算法的 要点浓缩 ,不包括成员变更和日志压缩。
5.0.1 状态
所有服务器 均保存以下 持久状态 (响应 RPC 请求前需要更新到 持久性存储介质 ):
| 参数 | 含义 |
|---|---|
| currentTerm | 服务器当前任期编号,即其所见最新任期编号(第一次启动时初始化为 0 ,后续单调递增) |
| votedFor | 在当前任期得到选票的候选人ID,不存在则为空 |
| log[] | 日志条目线性表;每个条目包含一条状态机命令以及领袖接到命令时的任期编号(索引从 1 开始) |
所有服务器 均保存以下 非持久状态 :
| 参数 | 含义 |
|---|---|
| commitIndex | 最后一个已提交条目的索引(初始化为 0 ,后续单调递增) |
| lastApplied | 最后一个已应用到状态机条目的索引(初始化为 0 ,后续单调递增) |
领袖 还保存以下 非持久状态 (选举后重新初始化):
| 参数 | 含义 |
|---|---|
| nextIndex[] | 记录各服务器一下发送条目的索引(初始化为领袖最后条目索引加一) |
| matchIndex[] | 记录各服务器最后复制条目的索引(初始化为 0 ,后续单调递增) |
5.0.2 AppendEntries RPC
领袖调用该 RPC 往其他服务器复制日志条目( 5.3 节讨论);也用于交换心跳( 5.2 节讨论)。
该 RPC 所需参数如下:
| 参数 | 含义 |
|---|---|
| term | 领袖任期 |
| leaderId | 领袖ID,属下后续可据此重定向客户端请求 |
| prevLogIndex | 上一条目索引 |
| prevLogTerm | 上一条目任期 |
| entries[] | 被复制日志条目(心跳则为空;出于性能考虑可以多个批量发送) |
| leaderCommit | 领袖已提交条目索引 |
该 RPC 返回值如下:
| 返回值 | 含义 |
|---|---|
| term | 接收者当前任期,领袖据此可更新自身任期 |
| success | 如果属下包含与 prevLogIndex 和 prevLogTerm 吻合的条目,则返回成功 |
接收服务器需实现以下处理逻辑:
- 如果任期编号比本地小 term<currentTermterm<currentTerm ,则返回失败( 5.1 节讨论 );
- 如果属下在 prevLogIndex 索引处不包含 prevLogTerm 任期条目,则返回失败( 5.3 节讨论 );
- 如果属下有条目与新条目冲突(索引相同任期不同),则删除该条目以及所有后续条目( 5.3 节讨论 );
- 追加所有未在日志中的新条目;
- 如果 leaderCommit>commitIndexleaderCommit>commitIndex ,则将 commitIndex 更新为 leaderCommit 以及最后新条目索引两者的较小值;
5.0.3 RequestVote RPC
候选人调用该 RPC 收集选票( 5.2 节讨论)。
该 RPC 所需参数如下:
| 参数 | 含义 |
|---|---|
| term | 候选人任期 |
| candidateId | 正拜选票的候选人ID |
| lastLogIndex | 日志最后条目索引( 5.4 节讨论) |
| lastLogTerm | 日志最后条目任期( 5.4 节讨论 ) |
该 RPC 返回值如下:
| 返回值 | 含义 |
|---|---|
| term | 接收者当前任期,候选人据此可更新自身任期 |
| voteGranted | 为真代表候选人收到接收者的选票 |
接收服务器需实现以下处理逻辑:
- 如果任期编号小于当前任期 term<currentTermterm<currentTerm ,拒绝该请求;
- 如果接收者 votedFor 为空或者等于 candidateId , 而且候选人日志至少与接收者本地一样新,则投出选票;
5.0.4 服务器规则
所有服务器
- 如果 commitIndex>lastAppliedcommitIndex>lastApplied , 则自增 lastApplied 并将 log[lastApplied] 条目应用到状态机;
- 如果 RPC 请求或响应所带任期比当前大 T>currentTermT>currentTerm , 则更新当前任期 currentTerm=TcurrentTerm=T ,并转成属下;
属下
- 响应来自领袖及候选人的 RPC 请求
- 选举超时时间耗尽而未收到当前领袖的 AppendEntries RPC 请求, 且未给其他候选人投票,则转为候选人;
候选人
- 转换到候选人后开始选举:
- 自增当前任期(编号);
- 为自己投票;
- 重置选举计时器;
- 向所有其他服务器发起 RequestVote RPC 请求;
- 如果收到过半数服务器的选票,则成为领袖;
- 如果收到新领袖 AppendEntries RPC 请求,转成属下;
- 如果选举(计时器)超时,重新发起选举;
领袖
- 赢得选举后,空闲时循环发送空 AppendEntries RPC 请求(心跳),避免其他服务器选举超时 ( 5.2 小节 );
- 收到客户端命令后,往本地日志追加新条目, 等条目应用到状态机之后才向客户端响应结果( 5.3 小节 );
- 如果最后条目索引大于等于属下下个索引,即 lastIndex≥nextIndex , 则发起 AppendEntries RPC 追加从 nextIndex 开始的日志条目:
- 请求成功,则更新该属下 nextIndex 以及 matchIndex ( 5.3 小节 );
- 请求因日志不一致而失败:下调 nextIndex 并重试(直至成功, 5.3 小节);
- 更新 commitIndex=NcommitIndex=N ,如果数值 N 同时满足以下条件( 5.3 和 5.4 小节 ):
- N>commitIndexN>commitIndex ;
- 过半数属下 matchIndex 不小于 N 即 matchIndex[i]≥NmatchIndex[i]≥N ;
- log[N].term==currentTermlog[N].term==currentTerm ;
5.0.5 关键性质
Raft 算法保证以下 关键性质 永远成立(后续章节展开讨论):
- 选举安全性 :任意任期内最多只能选举出一个领袖( 5.2 小节);
- 领袖只追加 :领袖只能追加新日志条目;不能修改也不能删除已有条目( 5.3 小节);
- 日志拼接性 :两个日志某个条目索引相同且同任期相同,则前面的条目也完全相同( 5.3 小节);
- 领袖完整性 :日志条目只要被提交,后续任期领袖一定包含该条目( 5.4 小节);
- 状态机安全性 :服务器将日志条目应用到状态机后,其他服务器无法在相同索引下应用另一个不同条目( 5.4.3 小节);
5.1 Raft基础
Raft 集群由若干服务器组成; 5 是一个典型数字,可以容忍其中两台故障。 任何时刻,每台服务器都处于以下三种状态之一: 领袖 ( leader )、 属下 ( follower )以及 候选人 ( candidate )。 正常情况下,刚好有一个领袖,而所有其他服务器则都是属下。 属下 节点是被动的:他们自身不发起任何请求,相反只是简单响应领袖以及候选人的请求。 领袖 节点负责处理所有客户端请求(客户端请求属下节点将被重定向至领袖节点)。 第三种, 候选人 用来选举新的领袖,将在下节介绍。 图-4 展示了三种服务器状态以及转变方式:
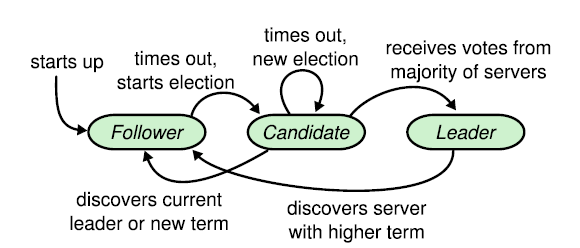
图-4 服务器状态 属下 ( followers )只响应来自其他服务器的请求。 如果一个属下没有收到任何通讯消息,它将成为 候选人 ( candidate )并发起一次新的选举。 收到集群过半数票的候选人将成为新的 领袖 。 领袖通常永久有效,除非故障。
Raft 将时间划分成长度任意的 任期 ( terms ),以连续整数进行编号,如 图-5 所示。 每个任期以一次选举开始,选举中一台或多台候选人尝试称为领袖,选举过程下节介绍。 一个候选人赢得选举后,在任期剩余时间以领袖身份服务。 在某些场景,选举会以 分裂投票 ( split vote )结束。 这种情况下,任期因领袖缺失而结束;新任期(以及新选举)不久后将开始。 Raft 确保任意任期内最多只有一个 领袖 。
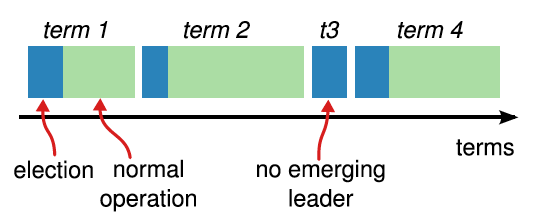
图-5 任期 时间划分成 任期 ,每个任期由一次 选举 开始。 每次成功选举后,一个 领袖 负责管理集群,直到任期结束。 有些选举会失败,这时任期没有选择领袖并结束。 不同服务器可能在不同时间点观察到任期更替。
服务器可能在不同时间点观察到任期更替,某些情况下也可能观察不到选举,甚至是整个任期。 任期在 Raft 中扮演 逻辑时钟 ( logical clock )的角色,辅助服务器检查过期信息,例如就领袖。 每台服务器保存当前任期编号,该编号永远单调自增。 服务器通讯时交换当前任期编号; 某台服务器任期编号比其他服务器小,那么它将更新自己的任期编号。 如果候选人或者领袖发现自己任期过期,将立即转换到属下状态。 如果某台服务器收到一个带旧任期编号的请求,它将拒绝该请求。
Raft 服务器通过 远程过程调用 ( remote procedure call 缩写为 RPC )通讯, 共识算法只需两种不同的 RPC 。 候选人在选举期间调用 RequestVote RPC 争取选票(第 5.2 小节); 领袖在选举胜利后调用 AppendEntries RPC 来复制日志并且保持心跳(第 5.3 小节)。 服务器在没有收到响应时及时重发 RPC 并通过 并发 提升性能。
5.2 领袖选举
Raft 采用 心跳机制 来触发 领袖选举 。 服务器启动后,开始以 属下 角色运行。 只要它不断收到来自 领袖 或者 候选人 的 RPC 请求,便保持属下状态不变。 领袖发送周期性心跳(不带任何条目的 AppendEntries RPC 请求)给所有属下,以保持领导权。 如果属下超过一定时间( 选举超时时间 )没有收到任何通讯,它便假设当前没有可见的的领袖,进而发起新选举。
为发起选举,属下自增自身任期,并转换为候选人。 随后它为自己投票,同时向其他服务器发起 RequestVote RPC 请求。 候选人持续这个状态直到发生以下三种情形之一:
- 候选人赢得选举;
- 另一台机器以领袖身份连接候选人;
- 超过设定时间但未产生获胜者;
如果候选人在同个任期内收到集群内过半数机器的投票,它将赢得选举。 每台机器在一个任期内最多只能给一个候选人投票,先来先得( first-come-first-served )。 过半数原则保证特定任期内,最多只有一个候选人赢得选举( 选举安全性 )。 一旦候选人赢得选举,它将成为领袖。 随后它向其他所有服务器发送心跳信息,建立领导权并阻止新的选举。
在等待投票时,候选人可能收到其他服务器为宣示领导权而发来的 AppendEntries RPC 请求。 如果来源领袖任期至少与候选人一样大,候选人便认为领袖合法,并重回属下状态。 相反,候选人将拒绝 RPC 请求并继续保持候选人状态。
第三种情况是,候选人既没赢得选举,也没输掉选举: 如果多个属下同时转变成候选人,选票可能会分裂,导致没有谁获得过半票。 这种情况下,候选人会超时并开启一次新的选举——自增任期并开始下一轮 RequestVote 请求。 然而,如果没有额外的信息,选票分裂可能会不断重复出现。
Raft 采用随机化选举超时时间,分裂投票 很罕见 ,就算出现也可 迅速解决 。 首先是防止投票分裂——在一个固定区间内(如 150-300 毫秒)随机选择一个超时时间。 这种做法的好处是,服务器超时时间被分散开,大部分情况下只有一台机器超时; 它将赢得选举并在其他机器超时前发送心跳。 其次是应对投票分裂,做法也是类似的。 每个候选人在选举开始时开启一个随机定时器,时间耗尽后才能发起下次选举; 这样便错开下次选举的时间,降低选票再次分裂的可能性。 第 8.3 节显示,这种方法选举领袖非常迅速。
选举是易理解性指导技术方案选择的一个典型例子。 起初,我们打算通过 排位 ( ranking )来解决: 每个候选人被赋予唯一位次,作为竞争时选择的依据。 如果候选人发现另一个候选人位次更高,它将重回属下状态。 这样一来,位次更高的候选人更容易赢得选举。 我们发现,这种做法会引入细微的可用性问题: 低排位服务器在高排位服务器故障时需要超时并转成候选人,过早超时将打断选举过程。 我们多次调整算法,但每次调整后均出现新的问题。 最终,我们得出结论:随机重试这个方案更直观,更好理解。
5.3 日志复制
领袖被选举出来之后,开始服务客户端请求。 每个客户端请求包含一个可以被复制状态机执行的命令。 领袖将命令最为新条目追加到本地日志,然后并行发起 AppendEntries RPC 请求往其他机器复制该条目。 一旦条目 安全 完成复制(已复制到过半数机器),领袖将把条目应用到自己的状态机并将执行结果告知客户端。 如果属下节点宕机、响应缓慢或者网络丢包,领袖将不断重试 AppendEntries RPC 请求(就算已经响应客户端),直到该节点日志同步。
日志组织方式如 图-6 所示。 每个日志条目包含一个状态机命令,以及领袖节点收到该命令时的任期编号。 任期编号用于检测日志的一致性,以保证 5.0.5 小节所列性质成立。 日志条目还包含一个整数索引编号,以区分其在日志中的位置。
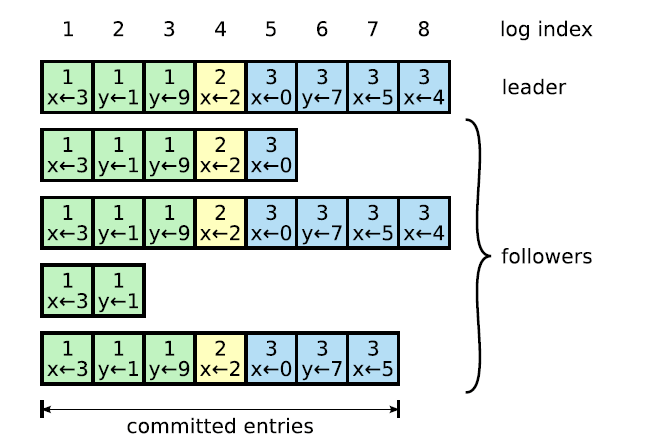
图-6 日志结构 日志由日志条目组成,按顺序编号。 每个条目包含创建时的任期编号(见方格内)以及一条状态机命令。 只要条目能够安全地应用到状态机,便认为条目 已提交 。
领袖决定何时可以将日志条目安全应用到状态机;这样的条目称为 已提交 ( committed )。 Raft 保证所有已提交条目都是持久的,可以被所有可用状态机执行。 一旦日志条目被其创建领袖复制到集群内过半数机器,便视作 已提交 ( 图-6 第 7 条目 )。 与此同时,领袖日志内所有前置条目(包括前一领袖创建的那些),亦视作已提交。 第 5.4 小节讨论领袖重选对该规则的影响,表明这个定义是安全的。 领袖追踪其知悉的已提交条目最大索引,并在后续的 AppendEntries RPC 请求中告知其他服务器。 属下发现日志条目已提交后,将依次应用到其状态机。
我们这样设计日志复制机制,目的在于让不同机器上的日志保持高度一致。 这不仅简化系统行为使其更加可预测,而且是确保安全性的一个关键因素。 Raft 算法保证以下两个性质,一起构成 5.0.5 小节提到的 日志拼接性 :
- 如果不同日志内两个条目索引以及任期编号相同,那么存储的命令也相同;
- 如果不同日志内两个条目索引以及任期编号相同,那么所有前置条目也都相同;
第一个性质来自这样的事实: 给定任期内,领袖最多只能创建一条给定索引的日志条目;而且,条目在日志中的顺序不能修改。 第二个性质由 AppendEntries 请求进行的简单一致性检查来保证。 发起 AppendEntries 请求时,领袖顺便带上前一日志条目的索引以及任期编号。 属下节点如果找不到对应的条目,它将拒绝新条目。 一致性检查递归地发挥作用: 初始时,日志状态为空,满足日志拼接性; 一致性检查确保日志扩展时继续保证日志拼接性。 因此,只要 AppendEntries 成功返回,领袖便知道属下日志至少到新条目为止与自己保持一致。
正常情况下,领袖和属下是一致的,因此 AppendEntries 请求不会失败。 然而,领袖故障可能导致日志不一致(例如,旧领袖可能还没将日志复制到所有机器)。 图-7 展示了几种属下日志与新领袖不一致的情形。 属下可能缺少领袖拥有的某些条目,也可能包含一些领袖没有的条目,或者兼而有之。 日志缺失或者多余的情况可能会持续若干任期。

图-7 日志差异 当顶部领袖节点启动后,从属节点日志状态存在各种可能: a-f 。 每个格子表示一个日志条目;数字代表任期。 属下节点可能缺失部分日志条目( a-b ); 也可能包含多余的未提交日志; 或者同时出现( e-f )。 举个例子,情景 f 可能是这样产生的: 该服务器是任期 2 的领袖,追加了几个条目,但是还没提交就宕机了; 它迅速重启,在任期 3 继续担任领袖,又追加了若干条目; 在新条目提交前,服务器再次宕机,错过了接下来几个任期。
Raft 算法中,领袖强制其他服务器复制自己的日志,以此应对不一致。 这意味着,需要用领袖上的条目来覆盖属下日志中有冲突的部分。 5.4 小节将证明,日志覆盖是安全的,只须加多一条约束。
为了让属下日志与自己保持一致,领袖需要找到双方最后一个匹配的条目, 从该点开始删除属下所有不一致条目,并发送所有后续条目。 这些操作根据 AppendEntries RPC 返回的一致性检查结果视情况执行。 领袖为每台属下维护一个 nextIndex 变量,保存下一个发送给属下的日志条目编号。 当领袖刚开始服务时,将 nextIndex 设置为自己日志中下一个条目的索引( 图-7 中的索引 11 )。 如果属下日志与领袖不一致,下一次 AppendEntries RPC 请求一致性检查将失败。 请求被拒绝后,领袖将降低 nextIndex 并重试 AppendEntries RPC 请求。 最终 nextIndex 将到达一个双方日志都匹配的点(还可以用二分查找加快这个过程)。 这时, AppendEntries 请求将成功,请求将删除属下所有有冲突条目并从领袖日志追加新条目(如有)。 一旦 AppendEntries 请求成功,意味着属下日志与领袖一致,任期内后续时间也是如此。
协议可以进一步优化,以降低 AppendEntries 失败的次数。
在这种机制下,领袖开始服务后不需要进行任何特殊操作来重建一致性。 领袖只需正常开始工作,日志在经过 AppendEntries 一致性检查失败调整后将自动收敛。 领袖从不覆盖或者删除自己日志中的条目( 第 5.0.5 小节 领袖只追加 性质)。
这个日志复制机制展示了第 2 节中寻求的 共识 性质: 只要过半数服务器正常运行, Raft 就可以接收、复制以及应用新日志条目; 正常情况下,在集群内进行一轮 RPC 请求即可完成新条目复制; 若干响应缓慢的属下并不影响性能。
5.4 安全性
前面章节介绍了 Raft 算法如何进行领袖选举以及日志复制。 然而,目前讨论的方法还不足以保证每台状态机刚好执行相同的命令序列。 例如,一台属下可能在领袖提交新日志条目时故障,恢复后被选举为新的领袖,覆盖了旧领袖追加的条目; 结果很可能造成不同的状态机执行了不同的命令序列。
本节进一步补全 Raft 算法,为选举增加一些额外约束,规定哪些服务器可以被选为领袖。 约束条件确保对于任意任期,领袖均包含所有先前任期提交的日志条目( 领袖完整性 )。 在选举约束的基础上,我们进一步精确提交的定义。 最后,我们将证明 领袖完整性 ,看看它是怎么确保复制状态机正确运行的。
5.4.1 选举约束
任何依赖领袖的共识算法,领袖必须拥有所有已提交日志条目。 一些像 Viewstamped Replication 的共识算法,就算节点没有包含所有已提交日志,也可以被选为领袖。 这类算法均需要一些额外的机制,来识别缺失条目并往新领袖传输。 这个过程可以在选举时,或者随后进行。 这种做法的缺点是,增加了不少额外的操作,相应地提高了复杂性。 Raft 采用一种更简化的做法,选举保证新领袖必须包含先前任期所有已提交条目,无须传输缺失条目。 这意味着,日志条目只有一个流向,从领袖流向属下,领袖不会覆盖日志中已存在的条目。
Raft 通过选举过程阻止候选人赢得选举,除非它拥有所有已提交日志。 候选人想赢得选举必须与集群内大多数机器通讯,这意味着每个已提交条目必须出现在这些机器中至少一台。 只要候选人日志至少与其他大多数机器一样新( up-to-date ),它便一定拥有所有已提交条目。 RequestVote RPC 请求实现这个约束:该请求带有候选人日志信息,其他节点发现自己日志更新(即更加新, more up-to-date )则拒绝投票。
Raft 以日志最后条目的索引以及任期判断哪个日志更新。 如果最后条目任期不同,则任期靠后的更新; 如果最后条目任期相同索引不同,则索引大(日志更长)的更新。
5.4.2 提交前任条目
正如 5.3 节讨论的那样,只要日志条目被复制到大部分服务器,领袖便知道该条目已提交。 如果领袖故障时没来得及提交某个条目,后续的领袖将继续尝试复制该条目。 然而,领袖无法确定先前任期的条目已提交,就算已经复制过半数。 旧日志条目复制过半数,也有可能被新领袖覆盖, 图-8 就是一个例子。
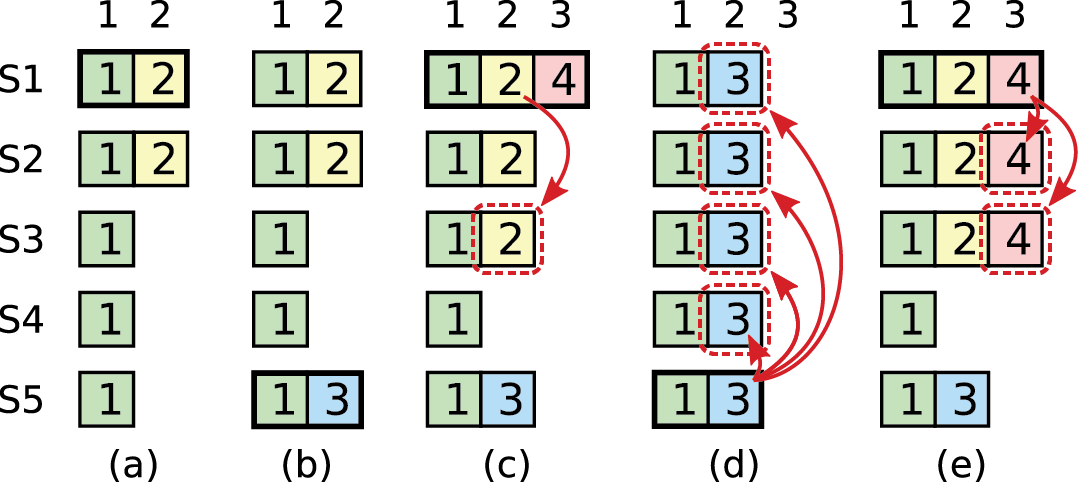
图-8 新领袖覆盖旧条目 时刻 a , S1 是领袖,只完成索引 2 条目的部分复制。 时刻 b , S1 故障; S5 被选为任期 3 的新领袖(取得 S3-4 以及自己的选票)并在索引 2 处接受一个新条目。 时刻 c , S5 故障, S1 重启并被选为领袖,继续进行复制。 这是,任期 2 的日志条目被复制到集群过半数机器,但没有提交。 如果 S1 在时刻 d 挂掉, S5 又一次被选为领袖( S2-4 的选票),将用自己任期 3 的条目进行覆盖。 但是,如果 S1 故障前将其当前任期的日志条目复制过半数机器,如时刻 e ,那么该条目便完成提交( S5 便无法赢得选举)。 此时,所有前置日志条目也都完成提交。
为了解决 图-8 问题, Raft 选择不继续复制提交前任条目。 只有领袖当前任期的日志条目才会持续复制提交; 一旦当前任期条目完成提交,所有更早的条目也被提交( 日志拼接性 )。 当然了,在某些场景下,领袖也可以安全地判断旧条目已提交(例如,旧条目已经复制到所有机器上)。 但是为了简化算法, Raft 采用了更加保守的处理策略。
为了让领袖复制前任条目时,保持原有的任期编号, Raft 引入了一些复杂性。 在其他共识算法中,新领袖复制前任条目,必须使用新任期编号。 Raft 的处理方式,日志条目在整个生命周期任期编号都不会变,因此推理起来更为简单。 此外,相比其他算法, Raft 领袖需要发送的前任条目更少了(其他算法为了修改任期编号必须重发)。
5.4.3 安全性论证
Raft 算法完整介绍后,我们可以更严密地论证 领袖完整性 (这个论证基于第 8.2 安全性证明)。 我们采用反证法来证明:先假设领袖完整性不成立,由此推导出矛盾结论。 假设任期 T 领袖在任期内提交了一个日志条目 e ,而后续任期领袖没有保存该条目。 设领袖不包含该条目 e 的最小任期是 U ( U > T ),则:
-
任期 U 领袖选举时就已经缺少条目 e (领袖不删除或者覆盖自己的日志) 。
-
任期 T 领袖将条目 e 复制过半数,而任期 U 领袖收到过半数投票。 因此至少有一台服务器( 投票人 )即接收了条目 e 又给任期 U 领袖投票,如 图-9 所示。 投票人是矛盾之所在。
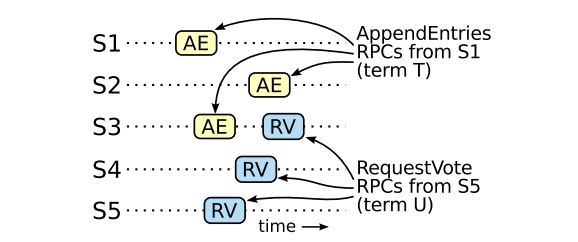
图-9 投票人矛盾 如果 S1 (任期 T 领袖)在任期内提交了一个新日志条目, S5 在任期 U 被选为领袖, 那么至少有一台机器接收了日志条目并且还给 S5 投票。
-
投票人必须在给任期 U 领袖投票前,便已接受任期 T 领袖提交的日志条目。 否则,它将拒绝任期 T 领袖的 AppendEntries 请求,因为其当前任期编号 U 比 T 更大。
-
根据假设,任期 T 到 U 之间的领袖均包含条目 e ,因此投票人在给任期 U 领袖投票时一定还包含条目 e 。 因为领袖永远不会删除自己的日志条目,属下只有在条目与领袖有冲突是才会删除。
-
投票人给任期 U 领袖投票,说明任期 U 领袖的日志至少和投票人一样新。 进一步推理存在两种可能的场景,均是矛盾的。
-
首先,如果投票人和任期 U 领袖日志最后任期相同,那么领袖日志至少与投票人一样长。 这与假设相矛盾,因为假设中投票人包含条目 e 而任期 U 领袖不包含。
-
还有一种可能的情况,任期 U 领袖日志最后任期只能比投票人大。 由于投票人包含了任期 T 条目 e ,其日志最后任期至少是 T ,因此任期 U 领袖日志最后任期比 T 大。 根据假设,提交任期 U 领袖最后一个日志条目的领袖,必须包含条目 e ( U 是不包含条目 e 的最小任期 )。 根据日志拼接性,任期 U 领袖一定包含条目 e 再次与假设矛盾。
-
这样便完成了整个证明过程。 因此任何任期比 T 大的领袖,一定包含所有在任期 T 创建并提交的日志条目。
-
日志拼接性保证未来的领袖也包含非直接提交的日志条目,如 图-8 时刻 d 。
在 领袖完整性 基础上,可以轻易证明 状态机安全性 以及状态机执行相同命令序列这个事实。
5.5 属下与候选人故障
到目前为止,我们的讨论主要集中在领袖故障。 属下或者候选人故障比领袖更容易处理,处理方式也是相同的。 如果属下或者候选人故障,发给它的 RequestVote 请求和 AppendEntries 请求将会失败。 Raft 应对这种失败的策略是不断重试:故障机器重启后,相关的 RPC 请求将成功。 如果服务器故障时正在处理 RPC 请求,但还没返回,恢复后也会收到同样的 RPC 请求。 Raft RPC 请求是 幂等的 ( idempotent ),因此这种重试不会造成任何影响。 举个例子,如果属下发现 AppendEntries 请求有条目已在本地日志中,这些条目将被忽略。
5.6 时序与可用性
Raft 还有另一个条件——安全性不依赖时序: 系统不能因为某些事件快于或者慢于预期发生便产生错误结果。 然而, 可用性 ( availability ,系统能够及时响应客户端请求 )却不可避免地依赖时序。 例如,如果消息交换耗时比两次机器故障间隔时间还长,候选人无法撑到选举胜出; 没有一个稳定的领袖, Raft 便不能工作。
领袖选举是 Raft 算法中受时序影响最大的部分。 只要以下时序条件成立, Raft 就可以选举并维持一个稳定的领袖:
broadcastTime≪electionTimeout≪MTBFbroadcastTime≪electionTimeout≪MTBF
不等式中, broadcastTime 是服务器往集群内所有其他服务器发起一轮并行 RPC 请求并收到响应的平均时间; electionTimeout 是第 5.2 节介绍的选举超时时间; 而 MTBF 是单台机器故障的平均时间间隔。 广播时间必须比选举超时时间小至少一个数量级,以便领袖可以可靠发送心跳信息确保属下不发起新选举; 与选举超时时间随机化配合,这个规则同时确保投票分裂不太可能发生。 选举超时时间必须比 MTBF 小若干数量级,这样系统运行才稳定。 领袖故障后,系统在重新选举前不可用,持续时间大约是选举超时时间;我们想要这部分时间占比尽量小。
broadcastTime 以及 MTBF 是由系统架构决定,而选举超时时间需要视情况选择。 Raft RPC 请求要求接收方确保数据写入持久性存储介质,耗时可能在 0.5ms 到 20ms 之间,由采用的存储技术决定。 因此,选举超时时间设在 10ms 到 500ms 之间比较合理。 正常情况下, MTBF 应该是若干个月甚至更长,完全满足不等式要求。
6 集群成员变更
到目前为止,我们假设集群配置(参与共识算法的服务器集合)是 固定 的。 实践中,偶尔需要调整配置,例如替换故障机器或者调整副本数等。 虽然可以通过暂停整个集群、修改配置、最后重启集群这种方式实现,但是调整期间服务 不可用 。 此外,有人工操作的地方就蕴含着误操作的风险。 为了规避这些问题,我们决定将配置变更自动化并将其作为共识算法组成部分合并到 Raft 中。
安全调整配置的前提是,调整过程中不能出现同时选出两个领袖的情况。 很不幸,任何服务器直接从旧配置切换到新配置的方案都是 不安全 的。 由于所有服务器不可能同时切换,集群在调整过程中可能分化出两个互斥的过半数集合(见 图-10 )。
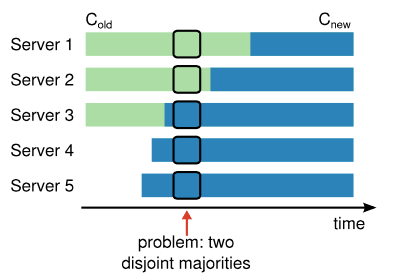
图-10 两互斥过半数集合问题 直接从一份配置切换到另一份配置是不安全的,因为不同服务器可能在不同时间点切换。 如图所示,集群机器从 3 台扩展到 5 台。 很不幸,有一个时间点可能造成同个任期内有两个不同的领袖被选出, 一个由旧配置( ColdCold )的过半数机器投票, 另一个由新配置( CnewCnew )的过半数机器投票。
为了确保安全性,配置变更必须分成 两阶段 ( two-phase )进行。 实现两阶段机制,有很多种方式可选。 譬如有些系统在第一阶段禁用旧配置并停止处理客户端请求,然后在第二阶段启用新配置。 在 Raft 中,集群先切换到一个称为 联合共识 ( joint consensus )的中间配置; 一旦联合共识提交,系统便可切换到新配置。 联合共识同时结合旧配置和新配置:
- 日志条目同时复制到新旧配置所有机器;
- 新旧配置中任一台服务器均可成为领袖;
- 决议 (选举和日志条目提交)必须 同时 由新旧配置机器 过半数 产生;
联合共识允许服务器在不同时间点单独切换配置,而不牺牲安全性。 而且在配置切换期间,集群对外服务不会中断。
集群通过特殊日志条目存储、传递配置; 图-11 描述了配置变更的全过程。 领袖接到将配置从 ColdCold 变更到 CnewCnew 的请求后, 将联合共识配置( Cold,newCold,new )作为日志条目保存并往集群其他机器复制(日志复制前面已介绍过)。 服务器一旦将新配置加入本地日志,后续便使用该配置进行决策(服务器使用本地日志中的最新配置,不管日志是否已提交)。 这意味着,领袖将使用 Cold,newCold,new 的规则决定 Cold,newCold,new 何时可提交。 领袖故障重选,新领袖可能是 ColdCold 配置或者 Cold,newCold,new 配置, 取决于选举前它是否已经接收到 Cold,newCold,new 条目。 无论如何, CnewCnew 在这期间肯定是无法独立决策的(需要联合 ColdCold )。
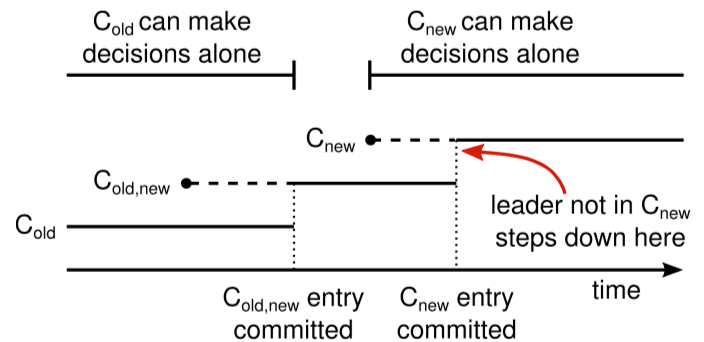
图-11 配置变更时间线 虚线表示已创建但未提交的配置条目,实线表示最后一个已提交条目。 领袖先创建 Cold,newCold,new 配置条目并提交到 Cold,newCold,new ( ColdCold 和 CnewCnew 同时过半数)。 然后,领袖创建 CnewCnew 配置条目并且提交到 CnewCnew 过半数。 这样一来,没有任何时间点 ColdCold 和 CnewCnew 有可能同时独立决策。
一旦 Cold,newCold,new 条目提交,无论是 ColdCold 还是 CnewCnew 均无法脱离对方单独决策。 根据 领袖完整性 性质,只有带有 Cold,newCold,new 条目的领袖才能被选为领袖。 现在,领袖可以安全创建 CnewCnew 条目并往整个集群复制。 同样,这个配置在每台接收服务器上即时生效。 当新配置在 CnewCnew 规则下提交(复制到 CnewCnew 过半数机器), 旧配置便可退出历史舞台,不在新配置中的机器可以停机。 如 图-11 所示,没有任何时刻 ColdCold 和 CnewCnew 能够同时独立决策; 这保证了安全性 。
在配置变更的过程中,还有三个需要考虑的问题。 第一个问题是,新服务器一开始可能没有任何存储日志条目。 如果它们以这种状态加入集群,可能需要挺长时间来追日志,这段时间内无法提交新条目。 为了弥补可用性缺口, Raft 在配置变更前引入一个额外的阶段。 在这个阶段内,新服务器作为 非投票 ( non-voting )成员加入集群复制日志(该阶段内新服务器不参与过半数判断)。 一旦新服务器跟上集群,配置变更便可开始。
第二个问题是,集群原领袖可能不在新配置内。 这种情况下,原领袖在提交 CnewCnew 条目后立即退出(转换到属下状态)。 这意味着,有那么一小段时间(提交 CnewCnew 时)原领袖在管理一个不包含自己的集群; 它复制日志考虑过半数约束时不能包含自己。 原领袖在 CnewCnew 提交后退出,因为这是 CnewCnew 开始独立生效的时间点( CnewCnew 能够安全选举新领袖)。 在此之前,有些情况下只有来自旧配置 ColdCold 的服务器可以被选为领袖。
第三个问题是,被移除的服务器(不在 CnewCnew 配置中)可能会干扰集群的正常运行。 这些服务器不再收到领袖心跳,因此它们会超时并发起新选举。 它们会以新任期编号发送 RequestVote RPC 请求,这会导致当前领袖转为属下状态。 最终还是会选出新领袖,但是被移除的服务器会再次超时并无休止地重复这个过程,严重影响性能。
为解决这个问题,服务器对当前领袖存活有把握时应该忽略 RequestVote RPC 。 准确讲,服务器在最小选举超时时间内收到过心跳,则说明领袖大概率还存活。 这时,就算接到 RequestVote RPC ,也不应该更新任期编号或者送出选票。 这不会影响正常的选举流程,因为服务器需要等待至少最小选举超时时间才会发起选举。 另一方面,领袖如果还能收到集群心跳响应,也不会被更大的任期编号废黜。 若干额外判断便可避免来自已移除服务器的干扰。
7 客户端及日志压缩
待续。
8 实现与评估
待续。
9 相关工作
待续。
10 结论
算法经常以 正确性 、 高效性 以及 简洁性 为设计目标。 这些目标确实很重要,我们认为 易理解性 同样重要。 只有研发人员能够将算法转化成具体实现,设计目标才能实现; 而实现不可避免需要从发表形式衍生而来并有所扩展。 除非研发人员对算法有深入理解,并形成开发思路,否则要实现相关特性谈何容易。
本论文以解决分布式共识相关问题为定位。 在这个领域,一些可行但令人费解的算法,如 Paxos ,已经困扰学生和开发人员多年。 为此,我们提出一种新算法 Raft ,比 Paxos 算法更容易理解。 我们也认为 Raft 为系统构建提供了更为坚实的基础。 以易理解性为主要目标,决定了 Raft 的设计思路; 设计过程中,我们多次用到几个小技巧,例如: 问题分解 以及 状态简化 。 这些技巧不但改善了 Raft 的易理解性,而且让我们更容易相信 Raft 的正确性。
11 鸣谢
略。
参考文献
- 原论文: In Search of an Understandable Consensus Algorithm
- 扩展版: In Search of an Understandable Consensus Algorithm (Extended Version)
【小菜学网络】系列文章首发于公众号【小菜学编程】,敬请关注:

