 小菜学编程
小菜学编程

为实现可靠传输,TCP 实现了接收确认机制:当数据发生丢包时,重传数据。当网络链路负载很重,甚至发生拥塞时,丢包就会很频繁。这时如果 TCP 还拼命地重传数据,将进一步压垮网络!
为了避免网络拥塞时压垮网络,TCP 还实现了 拥塞控制 机制,主要包含这几个算法:
- 慢启动
- 拥塞避免
- 快速重传
- 快速恢复
网络拥塞
每条网络线路都有一定的带宽上限,如果承载于其上的网络流量超过带宽,丢包就不可避免。这就是所谓的 网络拥塞( network congestion ),一种持续过载的网络状态,网络传输质量下降。
如下图,主机 ant 和 apple 之间有段链路发生网络拥塞,两台主机间的通信必然受到影响:

如果主机不知道网络拥塞的发生,还拼命地发送数据,最终肯定会进一步压垮网络链路。
拥塞控制
我们希望 TCP 能够根据网络链路的实时状态,自动调整发送速度,这就是 TCP 协议的 拥塞控制( congestion control )机制。拥塞控制机制细节很复杂,但原理却出奇的简单:
- 维护拥塞窗口,限制数据发送量;
- 根据网络当前状态,实时调节拥塞窗口:
- 如果长时间未收到 ACK 而发生数据重传,说明网络可能拥塞,缩小拥塞窗口,降低发送速度;
- 每收到一个有效 ACK 都增大拥塞窗口,提高发送速度,因为这通常意味着网络状态良好;
拥塞窗口
在流量控制一节,我们知道 TCP 通过 滑动窗口机制 来控制发送方的发送速度,以免打爆接收方的缓冲区。这个窗口也被称为 通告窗口 ,它规定了发送方此刻能够发送的最大数据量。
但滑动窗口只考虑接收方的缓冲区,对网络链路的拥塞程度则无能为力。因此,TCP 还维护了 拥塞窗口( congestion window ),根据链路的拥塞程度来约束发送速度。
拥塞窗口跟滑动窗口类似,同样规定了发送方此刻能够发送出去的字节数,只不过它通过评估网络链路的拥塞程度,并由一定的算法计算而来的。
拥塞窗口可缩写为 cwnd ,通常以 TCP 报文段为单位,表示还能发送多少个段出去。由于 最大报文段大小 缩写为 MSS ,有时也会以 MSS 为单位来讨论。
当网络链路比较顺畅时,拥塞窗口逐步增大,发送速度也就逐步提升;当网络链路发生拥塞时,拥塞窗口快速减小,发送速度急踩刹车,避免进一步压垮网络。
拥塞窗口跟滑动窗口并不冲突,前者避免压垮网络链路;后者则保证不打爆接收缓冲区。发送方某一时刻能够发送的最大数据量由两者共同决定,以较小的那个为准。因此,发送方实际发送窗口大小 W 为:
$W = min(awnd, cwnd)$
其中,awnd 为通告窗口大小,而 cwnd 为拥塞窗口大小。本节,我们假设通告窗口 awnd 足够大,重点考察拥塞窗口 cwnd 对 TCP 发送速度的影响。
那么,TCP 如何选择合适的 cwnd 呢?由于 TCP 连接建立之初,对网络容量和运行负载均一无所知。因此,它只能通过学习探测出一个合适数值:先不断提高发送速度,直到出现丢包(网络拥塞)。
TCP 学习 cwnd 的算法可以总结为:慢启动、拥塞避免、快速重传和快速恢复。
慢启动
TCP 连接刚建立后,它对网络链路的运行状况仍一无所知。为避免网络拥塞时火上浇油,TCP 先执行 慢启动( slow start )算法:将拥塞窗口 cwnd 初始化成最小的 1 个报文段,再随着数据 ACK 确认的达到慢慢扩张。
指数增长
在慢启动前期,TCP 每收到一个 ACK 确认,cwnd 就增加一个报文段。假设每个报文段都会回复 ACK 确认,在网络没有丢包的情况下,第一个分组被确认后,cwnd 就变成了 2 。
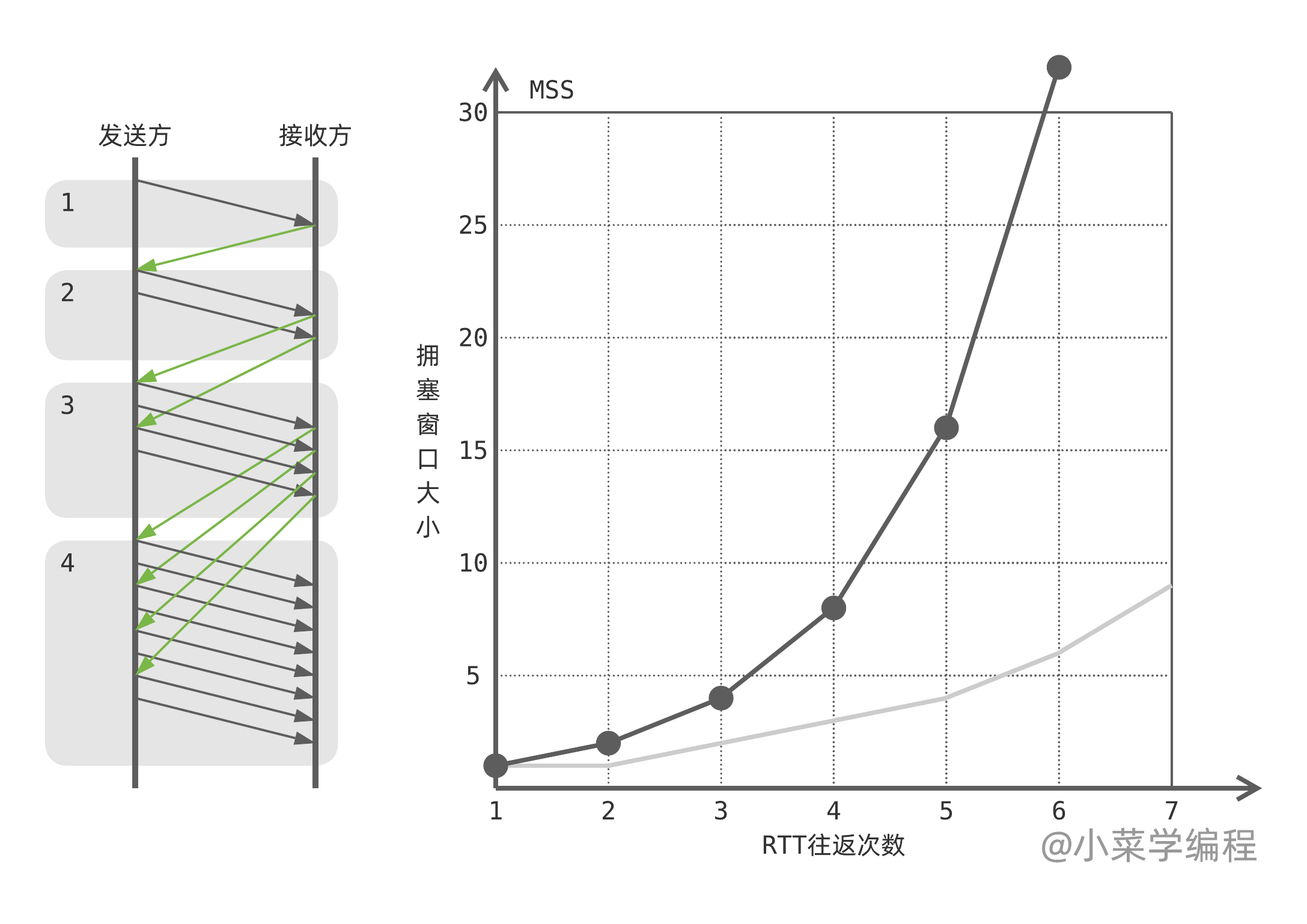
接下来,TCP 可以发送 2 个报文段。如果这 2 个报文段均顺利送到,可以收到 2 个 ACK 确认,cwnd 增大到 4 。再往下 TCP 可以发送 4 个报文段,若顺利收到 4 个 ACK ,cwnd 将增大至 8 。
以此类推,经过 $k$ 次往返后,拥塞窗口大小将达到 $cwnd=2^k$ 。因此,慢启动期间 cwnd 呈指数增长。指数型增长速度并不慢,所谓的慢启动其实是指拥塞窗口从一个较低的起点开始增长,而非一步到位。
接收方可能会开启 延迟确认( delayed ACK ),每接收两个报文段才回复一个 ACK 确认。这样的话,慢启动拥塞窗口仍呈指数函数增长,只是速度稍慢一些,如上图灰色曲线所示。
随着拥塞窗口 cwnd 快速增长,最终将变得太大而拖累网络,出现丢包现象。这时 cwnd 必须充分降低,通常至少要降低一半。此外,TCP 还会结束慢启动,进入 拥塞避免( congestion avoidance )阶段。
慢启动和拥塞避免阶段的切换点由拥塞窗口 cwnd 和 慢启动阈值( ssthresh )的相对关系决定:
- $cwnd < ssthresh$ ,执行慢启动;
- $cwnd > ssthresh$ ,执行拥塞避免;
- $cwnd = ssthresh$ ,执行慢启动或拥塞避免均可(边界无关紧要);
拥塞避免
通过慢启动,TCP 快速摸清当前线路的容量情况,进入稳定状态。这时,拥塞窗口 cwnd 是否就不需要再调整了呢?
答案是否定的,因为网络随时可能释放出更多的可用容量。假设网络容量被一个突发流量占用,导致同一链路下的所有连接都出现丢包,从而进入拥塞避免阶段。当突发流量消失,其他连接应该充分利用这些释放的网络容量。
为了能够温和地找出额外的可用容量,不对网络产生新的冲击,TCP 实现了 拥塞避免( congestion avoidance )算法。当拥塞窗口 cwnd 不低于慢启动阈值 ssthresh ,TCP 就执行该算法。
线性增长
在拥塞避免阶段,TCP 以更慢的速度扩张拥塞窗口,寻求额外容量。每当成功发送跟拥塞窗口大小等量的数据后,TCP 就给 cwnd 增加一个报文段。
假设当前拥塞窗口大小为 $k$ ,这时可以发出 $k$ 个报文段。当这 $k$ 报文段均顺利送达后,TCP 才给 cwnd 增加一个报文段。换言之,现在每收到一个 ACK 确认,cwnd 只增加 $\frac{1}{k}$ 个报文段。
举个例子,假设 TCP 进入拥塞避免阶段时拥塞窗口大小为 4 ,因此第一轮往返可以发出 4 个报文段。假设这 4 个段均成功送达并收到 ACK 确认,每个 ACK 确认为拥塞窗口增加 $\frac{1}{4}$ 个报文段,4 个 ACK 刚好增加 1 个报文段。
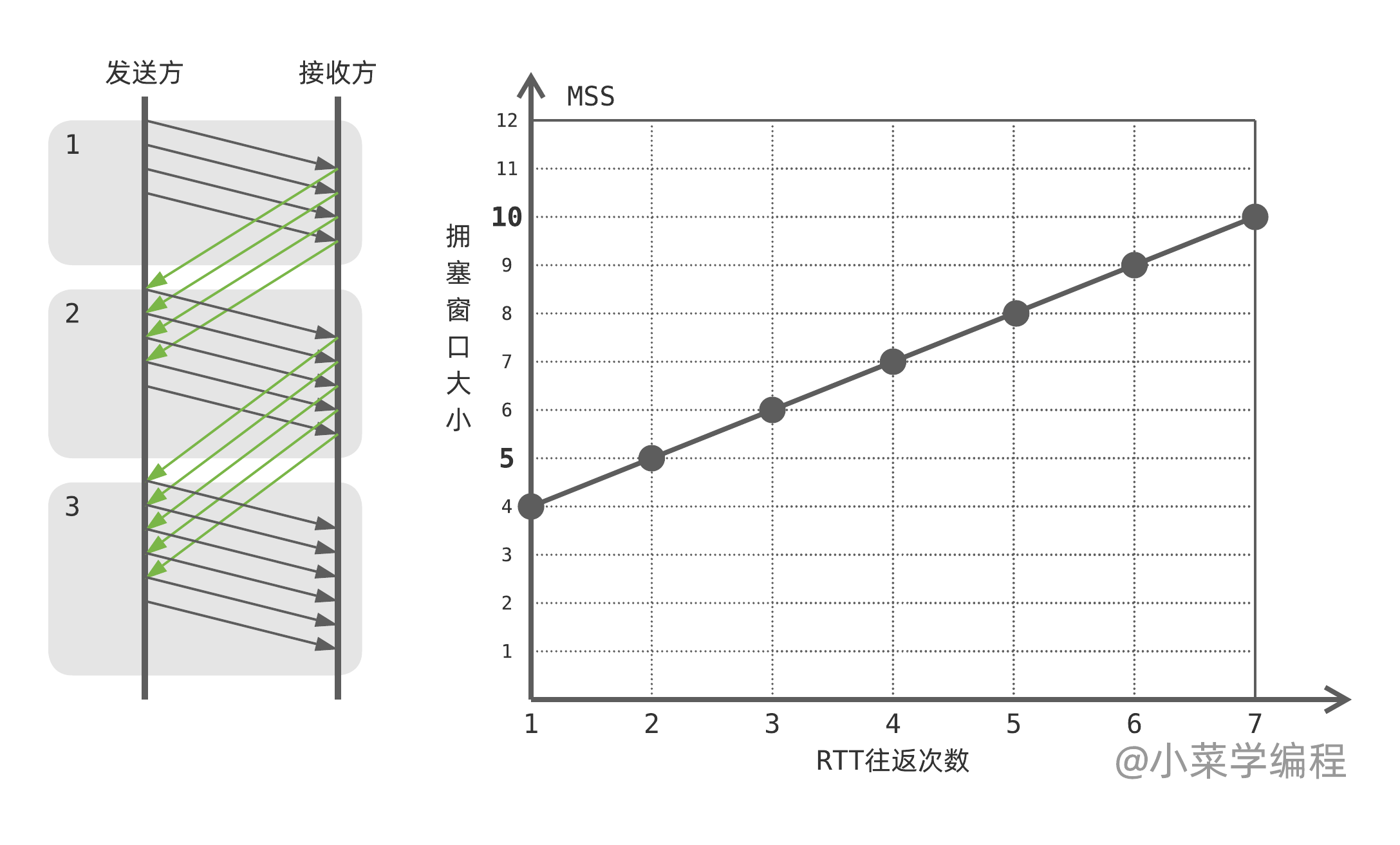
这样一来,第二轮往返可以发出 5 个报文段。如果这 5 个报文段也顺利送达并收到 ACK 确认,cwnd 又增加 1 个报文段。因此,第三轮往返可以发出 6 个报文段,其他依次类推。
很显然,拥塞避免阶段 cwnd 呈线性增长趋势。这种相对温和的扩张策略,既能有效利用网络释放的额外容量,又不至于给网络带来较大波动,可谓一举两得。
最后,我们通过一个曲线图,来进一步学习慢启动和拥塞避免的关系:
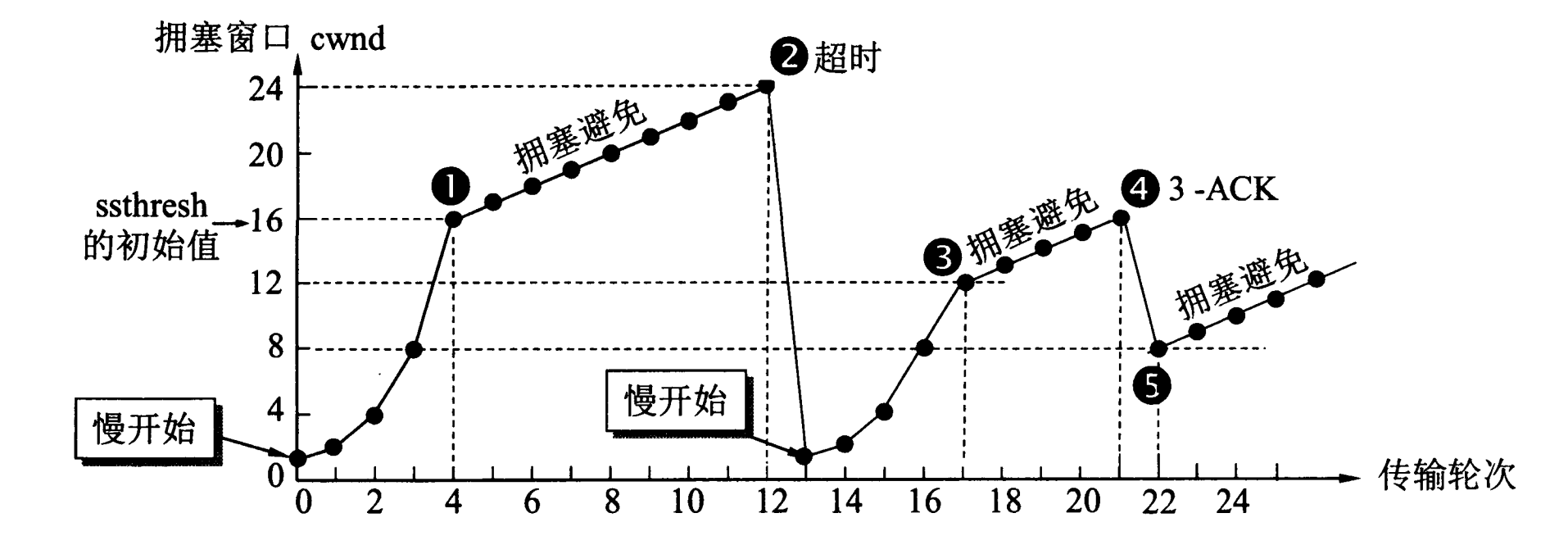
这个图片来自其他网络资料,慢启动在里面叫做“慢开始”,不影响理解。此外,我不清楚该图片的版权,如有侵权,请联系我删除。
TCP 最开始执行慢启动,早期实现会一直增长到出现拥塞才会停止。由于指数增长速度很快,慢启动阶段后期会有大量数据报文进入网络,引起不必要的网络拥塞。
因此,新版 TCP 实现会设置初始的 ssthresh ,慢启动达到该值就进入拥塞避免阶段。换句话讲,在造成网络拥塞之前,慢启动就提前进入更温和的线性增长阶段,对网络更友好。
进入拥塞避免阶段后,窗口保持缓慢增长。但遇到网络拥塞时(比如发生超时②),TCP 会将 ssthresh 设为当前拥塞窗口 cwnd 的一半,重新开始慢启动过程。
当慢启动增长到新的 ssthresh 后,切换为拥塞避免③,开始缓慢第寻找新的平衡点。当又遇到偶发丢包时(比如重复ACK④),又将 ssthresh 设为当前窗口的一半,直接进入拥塞避免(快速恢复)。
因此,ssthresh 就像是一个动态的参考基准,指导 TCP 更好地测量网络的容量。TCP 检测到网络拥塞,说明最佳的窗口大小应该比当前窗口小。因此将 ssthresh 设为当前窗口的一半,可以更好地提供指导。
快速重传
我们知道,TCP 实现可靠传输依赖的是 超时重传 机制。TCP 在发送完数据后,会启动一个定时器。如果在定时器超时前没收到接收方发来的 ACK 确认(认为数据丢了),就重传数据。于此同时,TCP 还会执行拥塞控制机制,将拥塞窗口 cwnd 减半。
我们来考察这样一个例子:发送方同时发出 5 个包,假设 2 号包丢了,其他包都顺利送达。3 、4 和 5 号包达到后,接收方应该发送确认,只是确认号仍是 1 号包。
换句话讲,发送方连续收到 1 号包的确认,说明 2 号包丢了。这时可以马上重传 2 号包及以后的数据,不用等待确认定时器超时,这就是所谓的 快速重传 算法。
收到重复的确认,说明发出去的数据发生丢包,意味着网络可能发生拥塞。TCP 同样会将 ssthresh 设为当前拥塞窗口 cwnd 的一半,并重新执行慢启动算法加以应对。
另外,TCP 为了提高传输效率,实现了 延迟确认 机制:收到数据时不会立即发送 ACK 确认,而是等一段时间,跟要发送的数据一起发出去。这样数据和 ACK 确认可共用一个分组报文,跟拼车一样更高效环保。
很显然,快速重传算法会受到捎带确认机制的制约。试想接收方刚好没有数据要发,因此 ACK 确认被延迟,乃至合并,发送方就不会检测到重复确认。
为了解决这个矛盾,TCP 规定接收方接到乱序数据后就立马发送 ACK 确认。回到前面的例子,接到 3 号包但 2 号仍未收到,这时就应该立马发送 ACK 确认,确认 1 号包。收到 4 跟 5 号包时,也是类似的,这样发送方就能检查到重复确认。
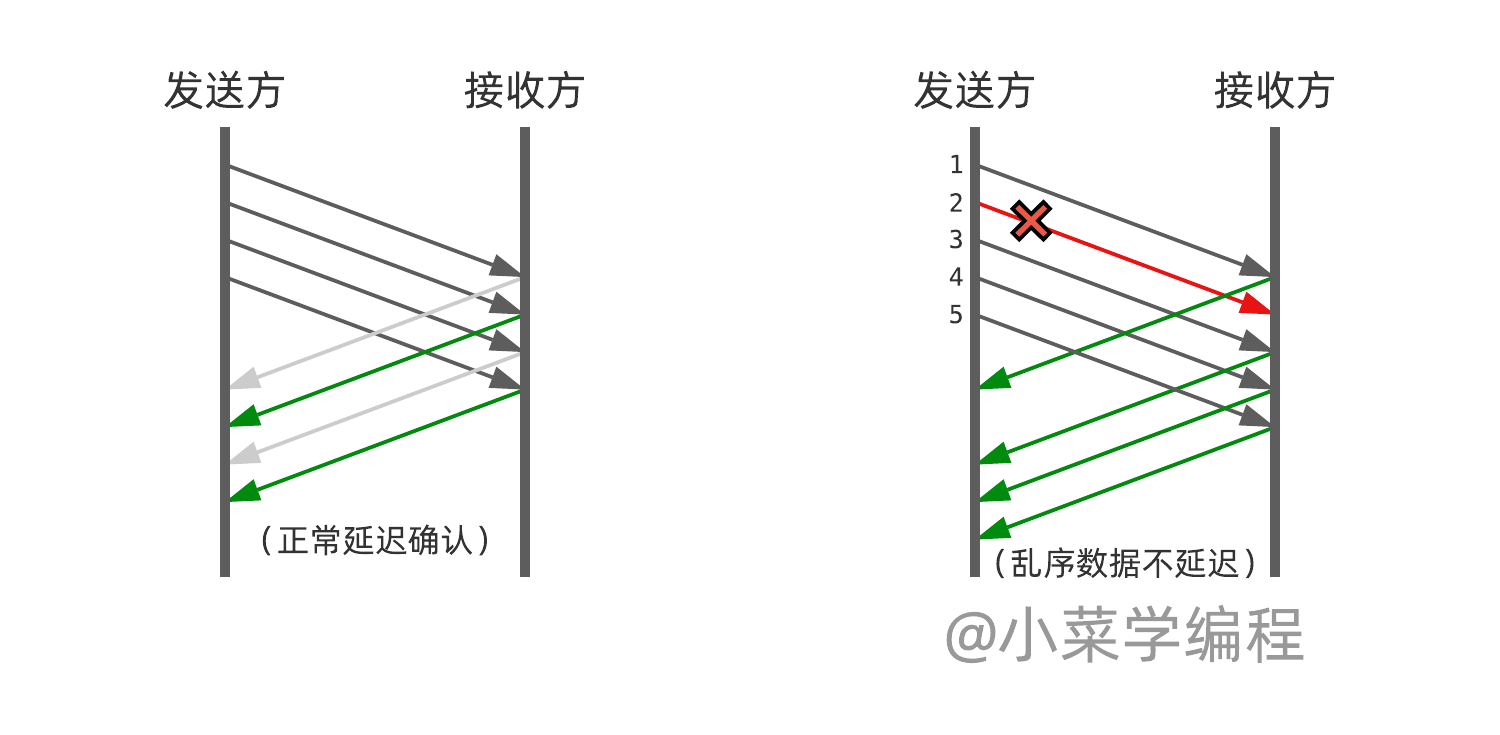
相反,如果没有这个机制,接收方收到 1 号包时,由于刚好没有数据要发送,延迟发送 ACK 确认。后续接到 3 、4 和 5 号包也是这样。最后等待一段时间还没有数据要发,TCP 才发送 ACK 确认,确认 1 号包。这样的话,发送方就不会收到重复确认,因此无法获悉 2 号包丢包的事实。
快速恢复
老版 TCP 实现一遇到丢包重传,就重新执行慢启动,发送速度一夜回到解放前。这种实现方式对 TCP 的发送效率影响很大,必须经历好几次往返,拥塞窗口 cwnd 才能恢复到原来的一半。
有时遇到的是偶发性丢包,网络不一定发生拥塞,这时执行慢启动是没有必要的。快速重传中收到重复确认的场景就是典型例子,虽然有包丢失了,但其后的包能正常送达说明网络应该还通畅。
因此,新版 TCP( Reno )选择跳过慢启动,直接进入拥塞避免阶段,这就是所谓的 快速恢复 :
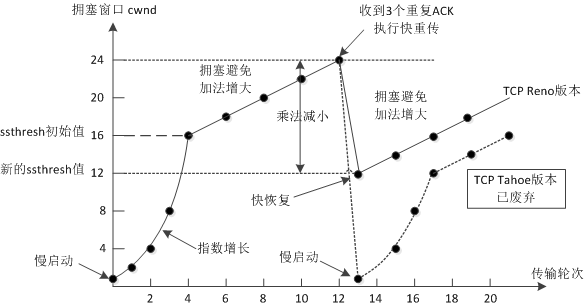
- 将 ssthresh 设为当前窗口的一半;
- 将当前窗口设为 ssthresh ;
- 执行拥塞避免,窗口大小线性扩张;
您可能会有疑问,如果网络真的出现拥塞,最佳的窗口大小在新的 ssthresh 下方怎么办呢?其实并无大碍,TCP 马上又会检测到网络拥塞,窗口和 ssthresh 又立马减半了。
实际上,在 TCP 检测到网络拥塞时,窗口和 ssthresh 都是立马减半,因而被称为 乘法减小 或者 指数退避 。每次降低一半,这种下降速度其实也是很快的。
【小菜学网络】系列文章首发于公众号【小菜学编程】,敬请关注:

