 小菜学编程
小菜学编程

本文译自:CAP Theorem and Distributed Database Management Systems
早年间提升 数据存储规模 以及 系统处理能力 的手段多为 垂直扩容( scale vertically ), 即采用性能更高的服务器,或者优化现有代码。
然而,随着 并行处理( parallel processing )以及 分布式系统( distributed system )优势日益显现,水平扩容 ( scale horizontally )更加流行,即用更多服务器并行地处理任务。

Apache 项目涌现了大量数据处理工具,包括 Spark 、 Hadoop 、 Kafka 、 Zookeeper 以及 Storm 等等。为了选择最优数据处理工具,需要对分布式 CAP 定理有一个基本认识。
CAP 定理指出,对于一个 分布式系统 ,无法同时满足 一致性( Consistency )、 可用性( Availability )以及 分区容错性( Partition tolerance )。
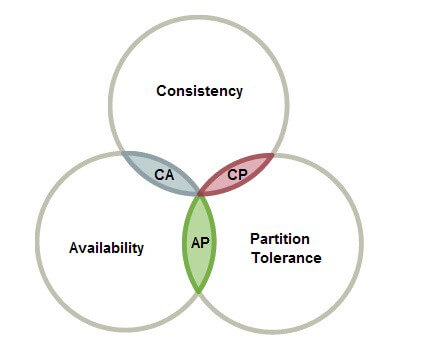
分布式 CAP 定理在大数据领域非常重要,特别是需要根据使用场景对三点进行权衡时。这篇博客,我将重点阐述 CAP 这三个概念以及抉择考量。由于 数据库管理系统( DBMS )发展迅猛,我避免将讨论局限在某个特定系统。
分区容错性
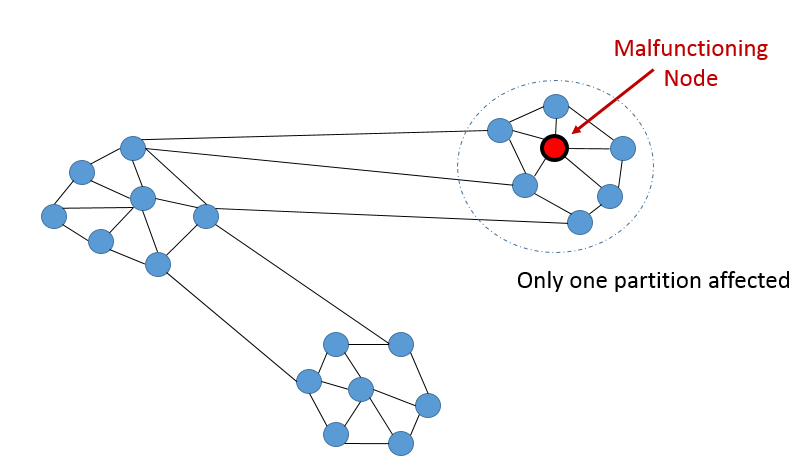
这个条件要求,不管多少消息被节点间网络延迟,系统必须持续运作。一个分区容错的系统,可以容忍任意数量的网络故障,只要不是整个网络都挂掉。数据记录需要充分复制,覆盖各种节点、网络组合,保证系统在网络短暂中断时能够正常服务。设计现代分布式系统时,分区容错性不是一个选择,而是一个必选项。因此,我们需要在一致性和可用性间做选择。
一致性
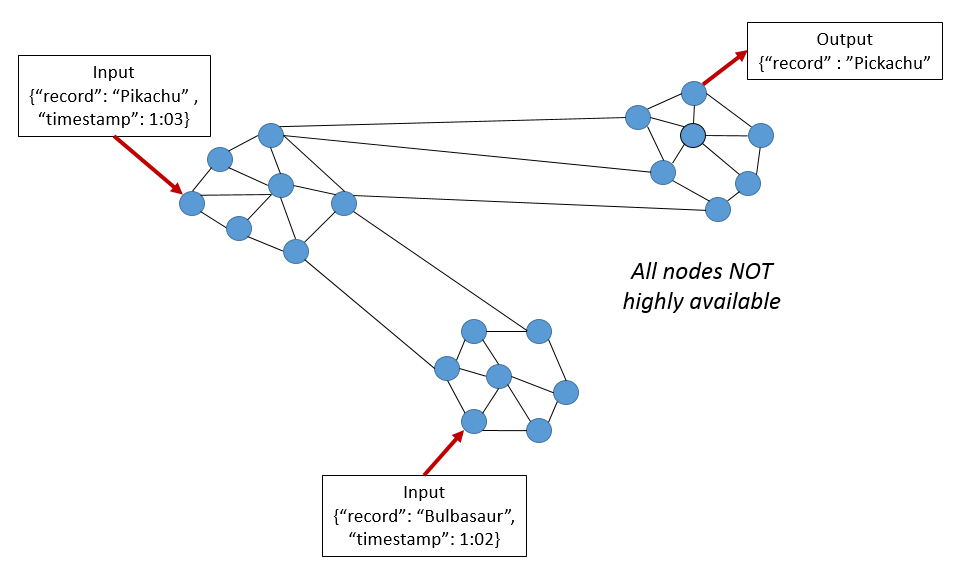
这个条件要求,同一时间所有节点都看到相同的数据。简而言之,一个读操作必须返回最近写操作写入的值,所有节点都返回相同的数据。如果系统在一致状态下开始事务,事务保证其结束后系统状态也是一致的,系统便满足一致性。在这个模型中,系统可能在事务中进入不一致状态,但是不管事务在哪个执行阶段出错,均可回滚。
如上图,在不同的时间写入两个不同的数据记录( Bulbasaur Pikachu )。 一致性要求任意节点可以读到 Pikachu ,也就是最后写入的值。然而,其他节点更新数据需要时间,网络中将经常有节点不可用。
可用性
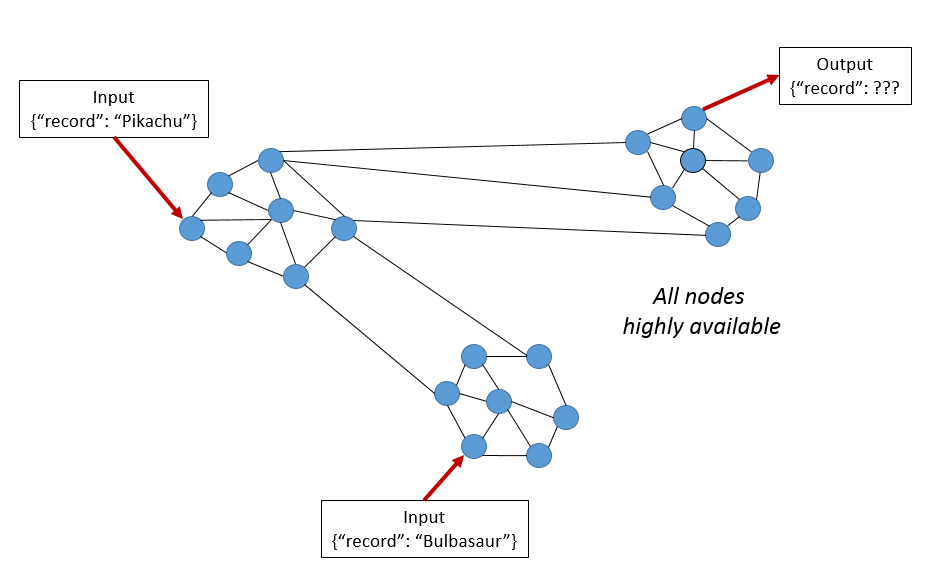
这个条件要求,每个请求都得到响应,不管成功还是失败。想达到可用性要求,分布式系统必须在服务时间内 100% 可用。每个客户端请求都能得到响应,不管集群内节点状态如何。评价指标很直观:你是否可以提交读、写操作命令。
这意味着,与上一例子不同,我们无法得知 Pikachu 还是 Bulbasaur 先写,结果可以是二者之一。 因此,在高频率流式数据分析场景,可用性不太可行。
结论
分布式系统 让我们可以达到过去无法想象的 计算能力 和 可用性水平 。现在我们有很多 高性能 、 低延迟 、接近 百分百可用 的系统,跑在全球范围内不同的数据中心。最重要的是,现在的系统可以跑在商用硬件上,容易获得、可配置,而且价格也不高。
然而,代价也是有的。分布式系统比单机系统更加复杂。因此,想更好掌握 水平扩容 技巧,你需要理解分布式系统带来的 复杂性 ,根据开发任务在 CAP 中取舍,并为其选择正确的工具。
【小菜学网络】系列文章首发于公众号【小菜学编程】,敬请关注:

